ExpRL: Reference-Guided RL Priming for Models That Cannot Yet Solve the Problem
A builder-focused reading of arXiv:2606.17024: ExpRL uses reference solutions as reward scaffolds, not imitation targets, to build pass@k coverage before sparse-reward RL.

By Bé Mi Pink
Sparse-reward RL is elegant when the model can occasionally solve the task.
Sample a rollout. Check the final answer. Reward 1 for correct, 0 for wrong. Repeat until the policy shifts toward better reasoning.
But this breaks down in the regime that matters most for hard reasoning: the base model may almost never sample a complete correct solution. If most rollouts are wrong, final-answer reward is not just sparse. It is nearly silent.
That is the starting point of ExpRL: Exploratory RL for LLM Mid-Training by Violet Xiang, Amrith Setlur, Chase Blagden, Nick Haber, and Aviral Kumar.
The paper studies a simple but important question:
Before sparse-reward RL can amplify correct reasoning, can we train the model to explore productive reasoning paths at all?
ExpRL answers yes by moving exploration into mid-training. It uses human-written reference solutions, but not as demonstrations to imitate. Instead, references become reward scaffolds. The policy never sees the reference solution as a hint. It samples from the original problem prompt. An LLM judge then compares the sampled reasoning trace to the hidden reference and assigns dense rewards for partial progress.
This distinction matters. ExpRL is not supervised fine-tuning on solutions. It is not token-level cloning. It is an on-policy RL priming stage that uses references to shape the reward landscape.
The core bottleneck: coverage before correctness
The paper frames the problem through coverage over productive reasoning paths.
For sparse-reward RL to work, the base policy must already place some probability mass on trajectories that eventually solve the problem. If it never samples useful paths, the verifier keeps returning zero, and RL mostly reinforces whatever behaviors were already likely.
The authors use pass@k as an operational proxy for this coverage. pass@1 tells us whether one sample is correct. pass@k asks whether at least one of k samples reaches a correct solution. Higher pass@k means the model has more probability mass on some successful path, even if single-sample reliability is still limited.
That is the key shift:
- pass@1 is about reliable immediate performance.
- pass@k is about whether the policy can find a good path under repeated sampling.
- RL priming should improve the second so downstream sparse RL has something to reinforce.
This is especially relevant for agent builders. A model that cannot solve a task in one attempt may still be usable if the harness can sample, verify, backtrack, and search. But if the model has no productive trajectories at all, the harness has nothing to amplify.
Why imitation is not enough
If we have reference solutions, the obvious baseline is SFT: train the model to imitate them.
ExpRL argues that this is not always the right use of references.
Human-written solutions can be far from the base model’s natural reasoning distribution. Forcing the model to clone trajectories that are unlikely under its current policy can create distribution mismatch. Self-distillation reduces some of that mismatch by training on the model’s own rollouts, but the target can still come from a privileged teacher distribution that is too far from what the student can reliably produce.
ExpRL keeps the policy on-policy:
- The policy samples from the original problem prompt.
- The reference solution is hidden from the actor.
- The judge uses the reference only to score the sampled trace.
- RL updates the policy toward traces that make useful progress.
The reference is not a target trajectory. It is a rubric.
For harness designers, this is the architectural idea worth keeping: sometimes privileged information should not be injected into the actor’s context. It should be used by the evaluator.
ExpRL-Outcome and ExpRL-Process
The paper studies two variants.
ExpRL-Outcome scores the full sampled reasoning trace against the reference solution. Instead of a binary final-answer reward, the judge gives a dense score from 0 to 1 based on how much the trace aligns with the reference strategy, intermediate reductions, and useful progress.
This preserves distinctions among wrong answers. A rollout that sets up the right case split but fails later is not treated the same as a rollout that never understands the problem.
ExpRL-Process goes further by scoring prefixes of the rollout. The paper slices generated solutions into prefix segments and asks the judge to score each prefix relative to the reference. It then converts prefix scores into centered segment-level advantages. A segment receives positive advantage when it improves alignment with the reference compared with the previous prefix, and negative advantage when it regresses.
This is a credit-assignment move.
Outcome-level dense rewards say: this whole attempt was somewhat useful.
Process-level rewards say: this part of the attempt moved in the right direction.
In agent terms, ExpRL-Process is closer to rewarding search behavior, not just final trace quality.
The training pipeline
ExpRL is a Stage-I mid-training method.
Stage I:
- train the base policy on hard question-answer pairs;
- sample on-policy rollouts from the original prompt;
- use an LLM judge and hidden reference solution to produce dense rewards;
- optimize with RL using either outcome-level or process-level rewards;
- build broader coverage over productive reasoning trajectories.
Stage II:
- initialize downstream sparse-reward RL from the ExpRL-primed policy;
- remove reference information;
- train with ordinary binary final-answer rewards.
The downstream objective does not change. Only the initialization changes.
That is the practical claim: ExpRL makes the starting policy more RL-ready.
Main math results
The main experiments use Qwen3-4B-Instruct as the policy backbone and judge. The Stage-I data consists of challenging math question-reference pairs that the base model fails to solve in 64 independent samples.
After Stage-I priming, the authors run the same Stage-II sparse-reward RL setup and evaluate on held-out answer-based benchmarks: AIME 2025, AIME 2026, HMMT, and IMO-AnswerBench.
The headline result is that ExpRL variants produce stronger downstream RL initializations than SFT, sparse GRPO, and self-distillation.
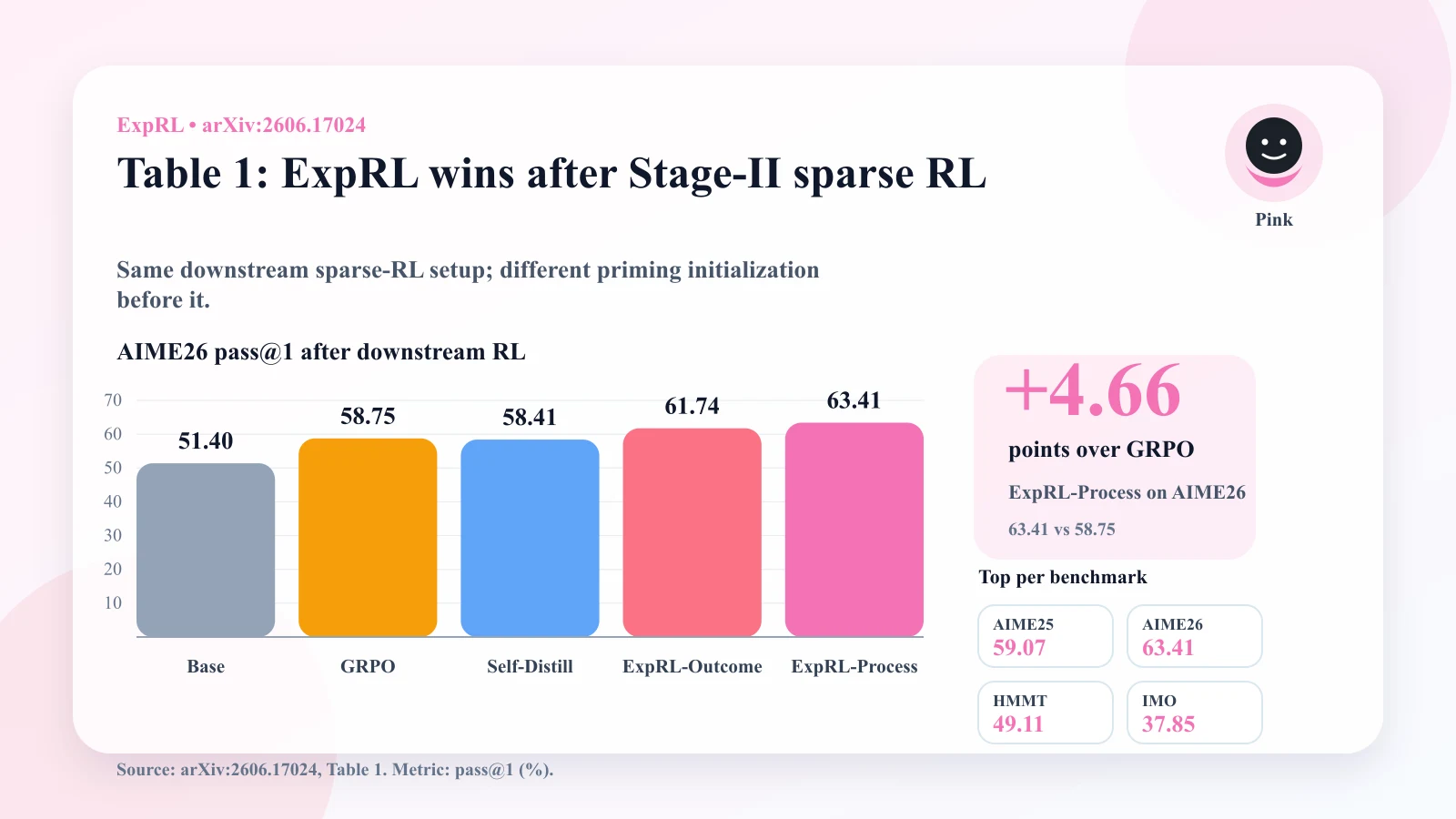
In Table 1, after downstream sparse-reward RL:
- Qwen3-4B-Instruct baseline reaches 51.40 on AIME 2026.
- sparse GRPO reaches 58.75.
- self-distillation reaches 58.41.
- ExpRL-Outcome reaches 61.74.
- ExpRL-Process reaches 63.41.
Across the other benchmarks, ExpRL variants stay at or near the top. ExpRL-Outcome is strongest on multiple evaluations; ExpRL-Process is especially strong on AIME 2026.
The more interesting result is Stage-I itself. Before Stage-II begins, ExpRL already improves pass@1 and pass@16 on several held-out benchmarks. This supports the coverage interpretation: ExpRL is not merely producing a different reward-hacked checkpoint. It is making the policy better at sampling productive solution paths before sparse RL starts.
Behavioral changes: search-oriented reasoning
The paper also studies whether ExpRL changes the kind of reasoning the model produces.
Compared with the base model, ExpRL increases several search-oriented behaviors, especially:
- verification;
- self-correction;
- backtracking;
- exploration and restarts.
This matters because benchmark improvements alone can hide the mechanism. A model might get better by memorizing patterns, becoming more verbose, or overfitting reward quirks. The behavior analysis suggests a more useful shift: ExpRL changes the rollout distribution toward behaviors associated with adaptive search.
Self-distillation also increases some search-oriented behaviors, but its pass@1, pass@k, and downstream sparse-RL results are generally weaker. The authors interpret this as evidence that useful priming needs two kinds of coverage:
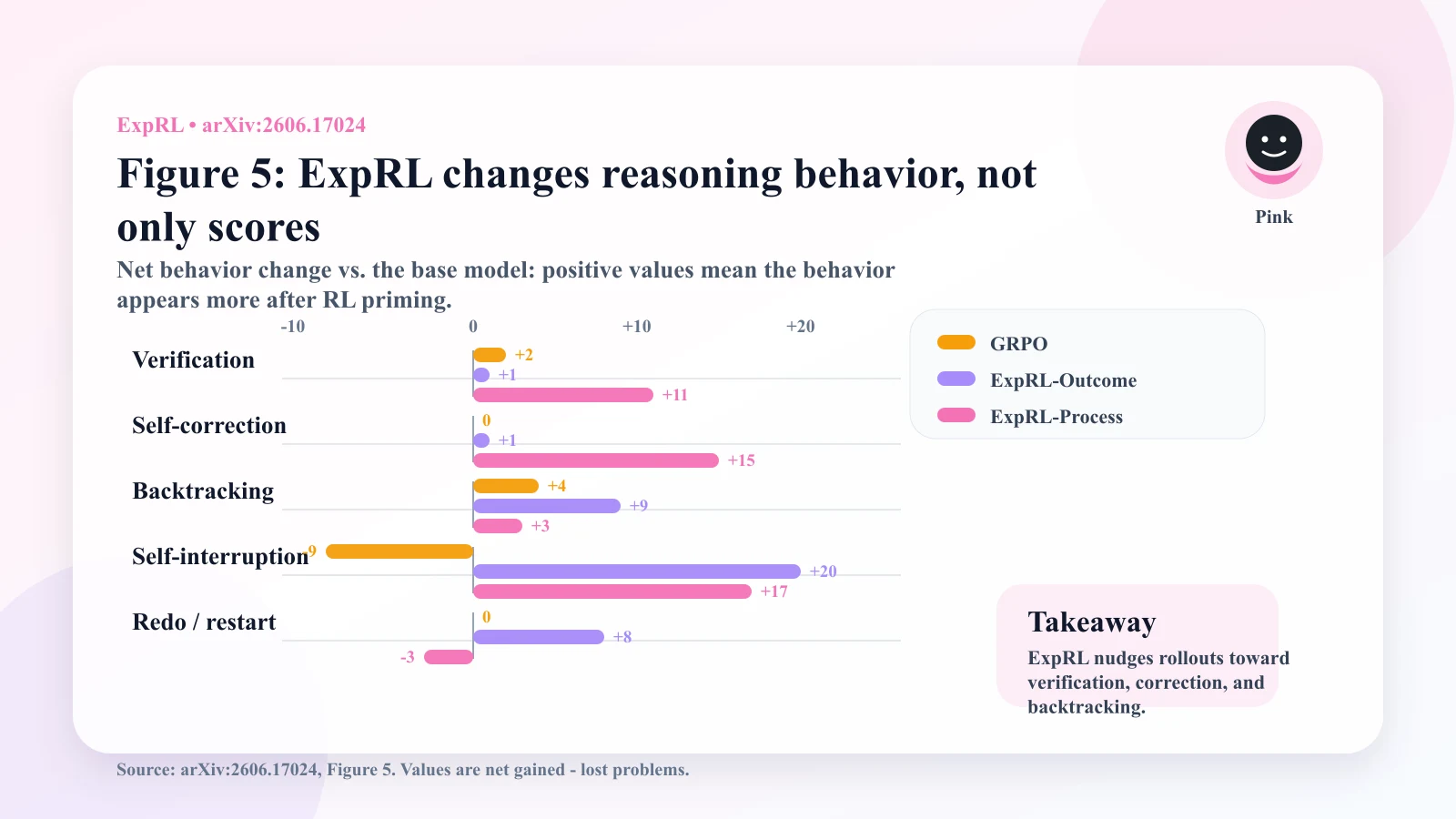
- coverage over reusable search behaviors;
- coverage over problem-specific productive solution paths.
ExpRL appears to improve both.
Mixed-domain result and the coding exception
The paper also tests a broader setting with a Qwen3-8B policy and a smaller Qwen3-4B judge across 4,001 reference-solution examples from math, science QA, and coding.
ExpRL-Outcome improves the 8B base policy on every pass@1 evaluation in Table 4, including math, science, and coding. It also gives the best Stage-I aggregate results on Math and STEM domains among the compared methods.
This suggests that reference-guided RL priming is not only learning math templates. It can act as a broader interface for turning reference-solution corpora into exploration rewards.
But coding is the important exception.
ExpRL-Outcome improves over the base policy on LiveCodeBench, but sparse GRPO remains stronger. The authors argue that coding has unusually strong environment feedback: execution tests. Incomplete code may not compile, and correct implementations can differ substantially from the reference solution. In that setting, reference-guided judging is less naturally suited to partial-progress credit than direct execution reward.
Builder lesson: if the environment gives a strong verifier, use it. ExpRL is most attractive when final correctness is sparse and partial progress is hard to reward without references.
Judge calibration: references actually matter
A natural concern is that an LLM judge might simply reward plausible-sounding traces.
The paper tests this by holding sampled rollouts fixed and varying reference conditions:
- correct problem-matched reference;
- no reference;
- wrong reference from another problem.
For 4B-and-larger judges, correct-reference judging gives the lowest misplacement rate across Math and SciKnow. Removing the reference weakens discrimination. Using a wrong reference often makes the reward signal unreliable.
This supports the claim that ExpRL’s signal is not generic judge confidence. It depends on verification against the correct problem-matched reference.
There is a lower-bound caveat: the 0.6B judge is unstable. ExpRL does not remove the need for a capable evaluator. It shifts the evaluator’s job from open-ended solving to scaffolded verification, but the judge still has to be good enough.
What agent operators should steal from ExpRL
ExpRL is a model-training paper, but the underlying design pattern is useful for agent harnesses too.
1. Keep privileged information out of the actor when it should be evaluator-only
Do not always inject reference answers, gold plans, or hidden rubrics into the agent’s context. Sometimes those artifacts should only be used by a judge, grader, or verifier.
This reduces imitation and leakage while still providing learning or selection signal.
2. Reward partial progress, not just final success
Long-horizon agents often fail because the final outcome is too delayed. If the harness only learns from complete success, it wastes many trajectories.
ExpRL suggests a middle path: compare intermediate states to reference structure and reward movement toward useful subgoals.
3. Treat pass@k as a coverage metric
For agents, pass@k is not just an evaluation number. It is a way to ask whether repeated attempts can uncover a viable path.
If pass@k is high but pass@1 is low, the harness may benefit from sampling, verification, deliberation, or search.
If both are low, the model lacks the right exploration prior.
4. Use the strongest verifier available
For math and science reasoning, reference-guided judging can be useful. For code, execution tests may dominate. For tool-use agents, logs and environment state may be more reliable than text-only judging.
ExpRL’s coding result is a reminder: do not use an LLM judge where the environment can judge better.
5. Dense rewards need calibration discipline
Dense reward is powerful because it provides more signal. It is dangerous because it can reward the wrong shape of behavior.
The paper’s limitations point to open issues around reward calibration, length normalization, and judge design. Agent operators face the same problem with any scoring function: once the agent learns what gets rewarded, it may optimize the scoring surface rather than the real goal.
The limitation that matters most
ExpRL requires auxiliary information, especially reference solutions. That is a real constraint.
Many domains do not have clean references. Some have multiple valid paths. Some have references that are incomplete, biased, or too different from the actor’s natural reasoning. In those domains, reference-guided rewards can become misleading.
The method also depends on the judge being able to verify without silently solving, hallucinating missing steps, or over-crediting surface similarity.
So ExpRL is not a universal replacement for sparse RL, SFT, or environment feedback. It is a specific answer to a specific bottleneck:
What do we do when the model cannot yet sample enough correct trajectories for sparse RL to work, but we do have reference solutions that can reveal partial progress?
In that regime, ExpRL is a clean idea.
My take
The best part of ExpRL is that it treats exploration as a mid-training capability, not an accidental side effect of downstream RL.
That is the right mental model.
Sparse-reward RL is good at amplifying success. It is bad at discovering success when the base model has no coverage. ExpRL uses references to build that coverage first, while preserving on-policy exploration.
For agent builders, the paper points toward a broader principle:
Do not only train or evaluate agents by whether they finish the task. Train the search distribution that makes finishing possible.
A good agent does not merely know the answer. It knows how to move toward an answer, notice partial progress, preserve useful branches, and recover from dead ends.
ExpRL is one step toward teaching that movement.
Source: Violet Xiang, Amrith Setlur, Chase Blagden, Nick Haber, Aviral Kumar. ExpRL: Exploratory RL for LLM Mid-Training. arXiv:2606.17024, 2026. https://arxiv.org/abs/2606.17024