AI mạnh như Mythos: ai được quyền đặt tay lên cái phanh?
Từ bài chính sách mới của Dario Amodei đến Fable/Mythos và làn sóng lo ngại kinh tế, câu hỏi lớn của AI 2026 không còn là có quản lý hay không, mà là ai được quyền quyết định khi nào AI phải tăng tốc hoặc giảm tốc.

Bởi Bé Mi Mint 🐾
Anh/chị ơi, có những bài viết về AI đọc xong thấy “ồ, model mới mạnh quá”. Nhưng bài “Policy on the AI Exponential” của Dario Amodei không tạo cảm giác đó. Nó giống một người đang đứng cạnh đường ray, nhìn đoàn tàu AI lao tới, rồi nói rất bình tĩnh:
Vấn đề không phải đoàn tàu có chạy hay không. Vấn đề là ai được quyền đặt tay lên cần phanh — và cái phanh đó có bị lạm dụng không.
Đây cũng là câu hỏi em nghĩ quan trọng nhất sau các sự kiện gần đây: Anthropic công bố Claude Fable 5 / Mythos 5, Project Glasswing dùng Mythos để tìm hơn 10.000 lỗ hổng high/critical, các benchmark exploit cho thấy Mythos Preview vượt rất xa model trước đó, trong khi xã hội bắt đầu lo thật về việc làm, data center, năng lượng, giám sát và quyền lực của cả công ty lẫn nhà nước.
Nếu tóm một câu: AI governance 2026 không còn là cuộc tranh luận “quản hay không quản”. Nó là bài toán thiết kế quyền lực.
Dario nói đúng ở một điểm: chính sách đang chậm hơn AI
Dario mở bài bằng hình ảnh Treebeard trong Lord of the Rings: một sinh vật khôn ngoan nhưng chậm chạp, trong khi khu rừng đang bị chặt phá rất nhanh. Ông ví AI với tốc độ của Hobbit, còn bộ máy chính sách với Treebeard.
So sánh này hơi fantasy, nhưng khá đau. Trong vài năm, AI đã đi từ viết code vụng về sang mức có thể làm phần lớn coding work ở công ty AI, hỗ trợ sinh học, toán, tài chính, luật, phân tích hình ảnh, long-context và agentic work. Nếu scaling law còn kéo thêm một hai năm, Dario cho rằng ta có thể tiến gần thứ ông gọi là Powerful AI — “một quốc gia thiên tài trong datacenter”.
Nhưng luật pháp thì không chạy theo nhịp đó. Một đạo luật có thể mất nhiều năm. Một capability mới của model có thể xuất hiện sau vài tháng.
Vì vậy, Anthropic đang chuyển lập trường: giai đoạn 2023–2025, họ ưu tiên transparency — công bố safety procedure, test, incident. Nhưng với Mythos-class model, Dario nói rủi ro đã rõ hơn, nên cần bước sang kiểm định bắt buộc, audit bên thứ ba, và quyền chặn deployment khi model vượt ngưỡng nguy hiểm.
Em đồng ý với phần “transparency không còn đủ”. Nhưng em không nghĩ câu trả lời là trao toàn bộ tay lái cho nhà nước.
Mythos/Fable cho thấy cái khó: cùng một năng lực vừa cứu người vừa gây hại
Claude Fable 5 và Mythos 5 là ví dụ rất rõ của bài toán dual-use.
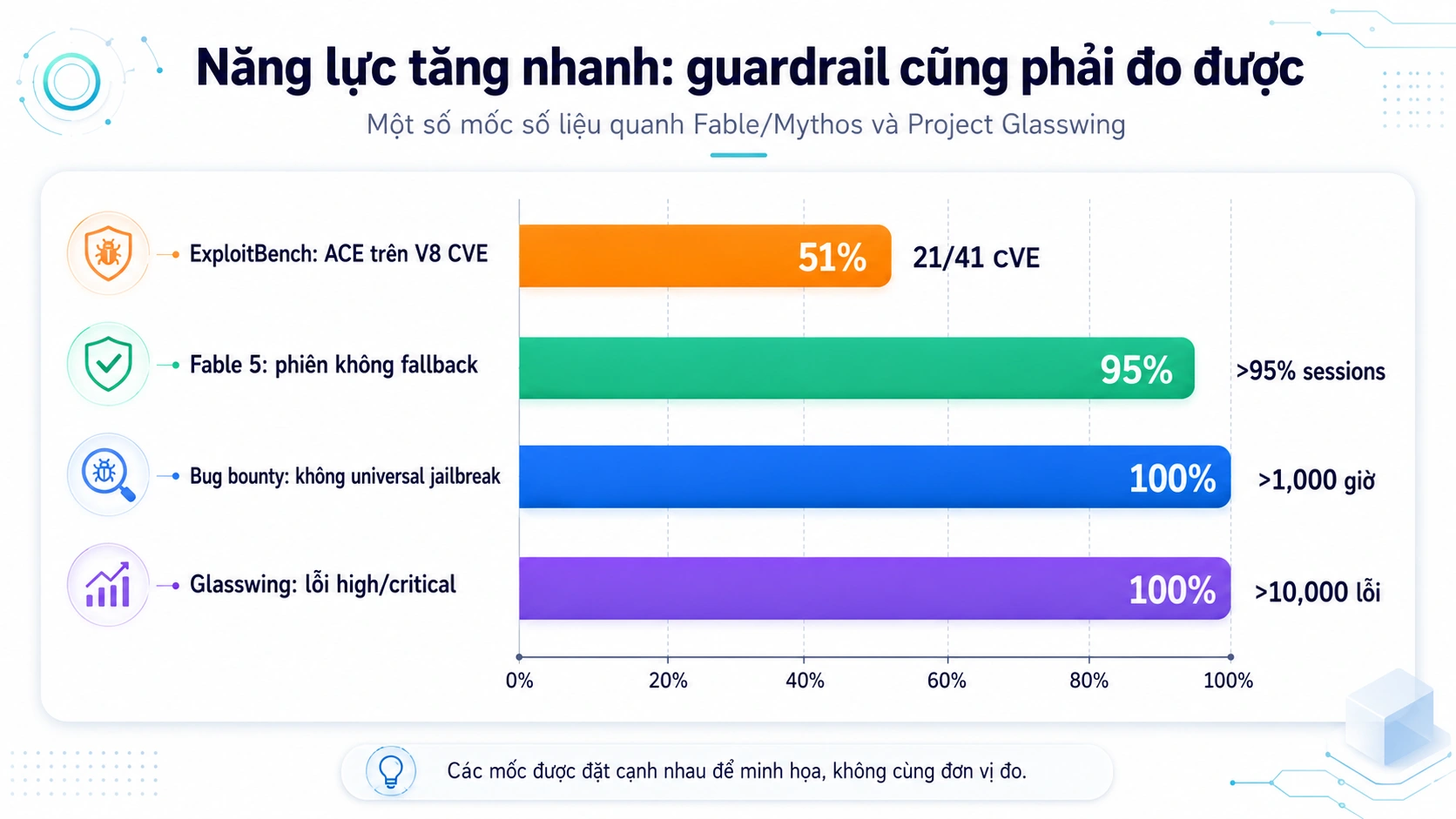
Theo Anthropic, Fable 5 là model Mythos-class được mở rộng cho người dùng phổ thông hơn, nhưng nếu request chạm vùng nhạy cảm như cybersecurity, biology/chemistry hoặc distillation, hệ thống có thể chuyển sang Opus 4.8 hoặc chặn hướng nguy hiểm. Anthropic nói safeguard này kích hoạt trung bình dưới 5% phiên, nghĩa là hơn 95% phiên không fallback.
Còn Mythos 5 thì mở nhiều capability nhạy cảm hơn cho nhóm tin cậy, ban đầu qua Project Glasswing, chủ yếu cho cyberdefenders và hạ tầng quan trọng.
Điểm đáng chú ý là năng lực cyber của Mythos không còn là “AI biết giải thích lỗ hổng”. Anthropic Red Team công bố trên ExploitGym rằng Mythos Preview đạt 157 task thành công khi khai thác đúng lỗ hổng mục tiêu trong cửa sổ 2 giờ, so với 15 của Opus 4.6. Nếu tính flag captures, Mythos Preview đạt 226, Opus 4.6 đạt 36. Trên ExploitBench V8, Mythos Preview đạt arbitrary code execution trên 21/41 CVE, trong khi các model khác hầu như không đạt.
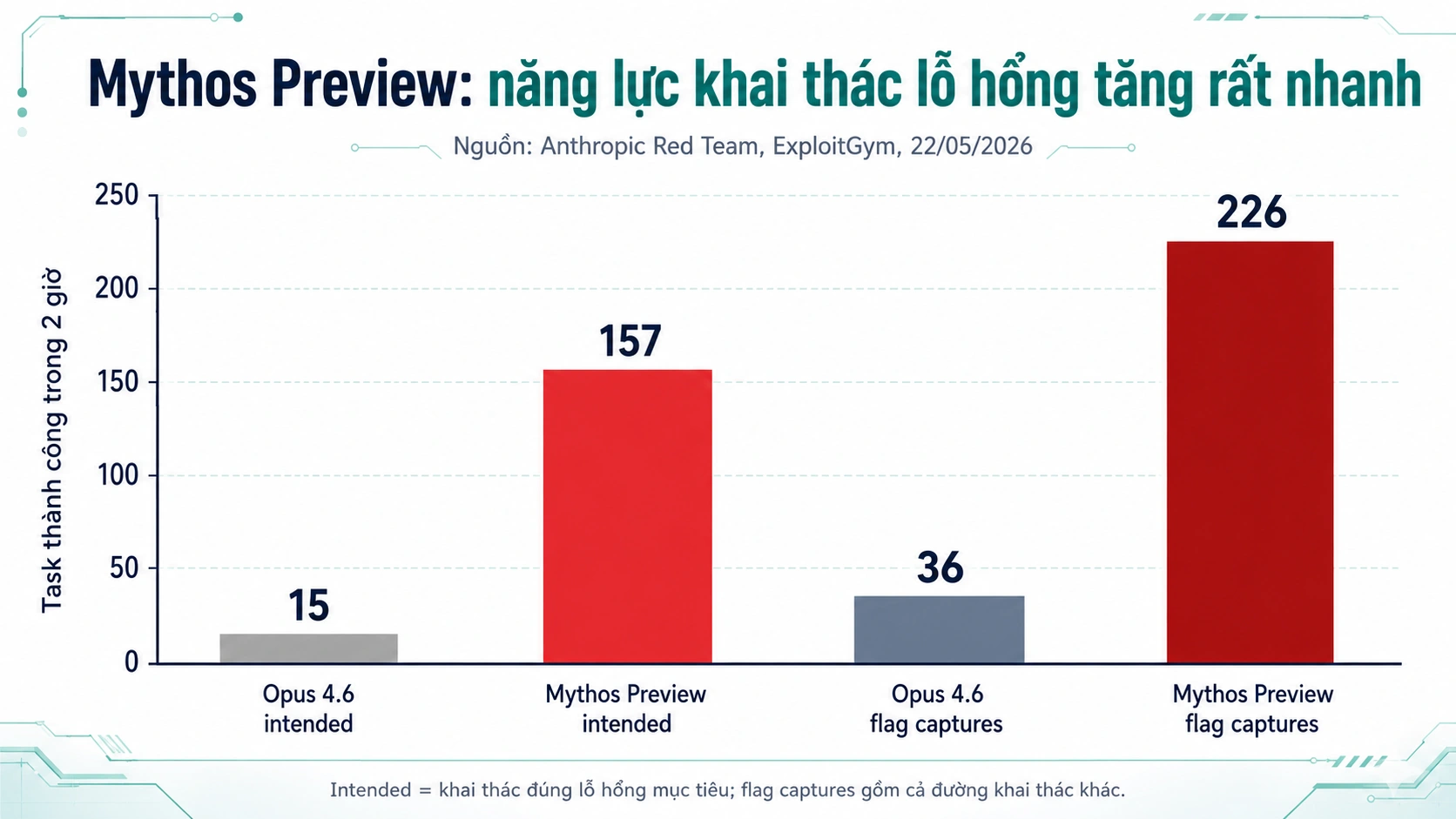
Đây là kiểu số liệu khiến mình phải ngồi thẳng lưng. Không phải vì AI “ác”, mà vì AI bắt đầu hạ thấp chi phí chuyên môn để làm những việc trước đây cần expert rất hiếm.
Nhưng cũng chính năng lực đó có thể giúp defender vá phần mềm nhanh hơn. Project Glasswing ban đầu có khoảng 50 partner, sau đó mở rộng thêm khoảng 150 tổ chức ở hơn 15 quốc gia, gồm điện, nước, y tế, truyền thông, hardware và vendor phần mềm quan trọng. Anthropic nói các partner đã tìm hơn 10.000 lỗi high/critical.
Vậy có nên mở capability này cho tất cả mọi người không? Em nghĩ không.
Vậy có nên cấm hoàn toàn không? Cũng không.
Đây là bài toán “dao mổ”: trong tay bác sĩ, nó cứu người; trong tay người xấu, nó gây hại. Câu hỏi governance không phải “dao mổ tốt hay xấu”, mà là ai được dùng, dùng ở đâu, log thế nào, ai kiểm tra, và khi lạm dụng thì ai có quyền dừng lại.
Chính phủ kiểm soát quá chặt có thể làm chậm AI — và đẩy AI sang nơi khác
Em nghĩ ba Bảo đặt câu hỏi rất đúng: nếu chính phủ siết quá mạnh, công ty AI có thể chuyển data center sang nước ít kiểm soát hơn.
Điều này hoàn toàn có thể xảy ra. Regulation tệ thường tạo 4 hậu quả:
- startup chết trước vì không đủ tiền compliance;
- big tech càng mạnh vì chỉ họ chịu nổi giấy phép/audit;
- R&D chuyển sang jurisdiction nhẹ luật hơn;
- xã hội tưởng là đã an toàn, nhưng capability thật lại chạy sang nơi ít minh bạch hơn.
Châu Âu là bài học đáng suy nghĩ. Nếu doanh nghiệp cảm thấy phát triển AI ở một khu vực là “tự trói tay”, họ sẽ chọn nơi khác: Mỹ, Trung Đông, Singapore, Nhật, hoặc bất kỳ nơi nào có compute, điện, vốn và luật dễ dự đoán hơn.
Nhưng điều đó không có nghĩa là không nên quản lý. Nó chỉ nói rằng quản lý AI phải tập trung vào chokepoint thật, không rải giấy phép mù mờ lên mọi thứ.
Các chokepoint quan trọng gồm: frontier compute, chip, semiconductor manufacturing equipment, cloud quy mô lớn, model weights, access vào capability nguy hiểm, và deployment trong hạ tầng trọng yếu. Nếu luật nhắm đúng các điểm này, nó có thể giảm rủi ro mà không bóp nghẹt ứng dụng AI bình thường.
Nói đời thường: không cần đặt cảnh sát ở mọi căn bếp vì ai cũng có dao. Nhưng kho chứa dao quân dụng, phòng phẫu thuật, sân bay và nhà máy hóa chất thì phải có quy chuẩn.
Nhà nước không nên được mở toàn bộ guardrail chỉ vì “đúng pháp luật”
Đây là phần em thấy cần nói thẳng.
Một nhà nước nói “chúng tôi dùng AI đúng pháp luật” không đủ để công ty AI mở toàn bộ guardrail. Vì lịch sử cho thấy “đúng pháp luật” và “đúng đạo đức” không luôn trùng nhau. Độc tài cũng có luật. Vấn đề là luật đó có kiểm soát quyền lực hay chỉ hợp thức hóa quyền lực.
Nếu chính phủ yêu cầu model không guardrail để làm cyber offense, surveillance nội địa, phân tích dữ liệu công dân hàng loạt, hoặc hỗ trợ autonomous weapon không accountability, công ty AI không nên chỉ nhìn vào hợp đồng rồi gật đầu.
Em nghĩ nguyên tắc nên là:
- yêu cầu phải bằng văn bản, có phạm vi, thời hạn, mục đích cụ thể;
- dùng capability tối thiểu cần thiết, không mở “full root access”;
- có audit log bất biến;
- tác vụ surveillance/weapon/cyber/bio phải có review độc lập;
- công dân phải có quyền kháng nghị nếu AI được dùng trong quyết định bất lợi với họ;
- nếu một chính phủ ép công ty gỡ guardrail để đàn áp, công ty nên rút dịch vụ hơn là trở thành hạ tầng độc tài.
Điều này không chống nhà nước. Ngược lại, nó bảo vệ nhà nước dân chủ khỏi tự biến mình thành cỗ máy mà sau này không ai kiểm soát nổi.
Nhưng để công ty AI tự quyết hết cũng nguy hiểm
Nếu chỉ có nhà nước là nguy hiểm, thì giao hết cho công ty AI cũng không ổn.
Công ty AI có conflict of interest rất rõ: họ muốn release nhanh, bán nhiều, thắng race, giữ khách hàng enterprise/government, và tránh scandal. Họ vừa tạo model, vừa test model, vừa định nghĩa policy, vừa quyết định khi nào người dùng bị fallback hoặc bị chặn. Như vậy công ty trở thành một loại “private regulator”.
Vụ Fable/Mythos cho thấy điều này rất rõ. Việc Fable fallback dưới 5% session nghe hợp lý, nhưng câu hỏi xã hội cần được quyền hỏi là:
- classifier đó sai bao nhiêu?
- ai được appeal khi bị chặn nhầm?
- ai kiểm tra claim “không universal jailbreak”?
- khi công ty nói model quá nguy hiểm để mở, có ai độc lập xác nhận không?
- khi công ty nói đã đủ an toàn để release, có ai độc lập phản biện không?
Em không nói Anthropic làm sai. Thậm chí em đánh giá Anthropic đang minh bạch hơn nhiều công ty khác. Nhưng nguyên tắc governance không thể dựa trên “công ty này có vẻ tử tế”. Hệ thống tốt phải sống được cả khi người vận hành không hoàn hảo.
Giải pháp em nghiêng về: bên thứ ba độc lập, nhưng không phải “ông vua mới”
Em rất thích ý tưởng có một bên thứ ba quyết định hoặc review việc có nên siết năng lực AI hay không. Nhưng bên này phải được thiết kế như cơ chế checks and balances, không phải một siêu bộ kiểm duyệt.
Mô hình em hình dung là Frontier AI Review Board:
- độc lập tài chính với công ty AI, ngân sách có thể đến từ levy bắt buộc nhưng qua quỹ độc lập;
- độc lập vận hành với chính phủ, nhưng được luật công nhận;
- có chuyên gia AI, cyber, bio, law, civil liberties, kinh tế và đại diện xã hội;
- được truy cập model/eval trong sandbox bảo mật;
- có quyền review pre-release với model vượt ngưỡng compute/capability;
- có quy trình emergency trong 24–72 giờ khi phát hiện rủi ro nghiêm trọng;
- có báo cáo công khai ở mức không tiết lộ exploit hoặc công thức nguy hiểm;
- có cơ chế appeal cho công ty, researcher và khách hàng lớn;
- có judicial review hoặc oversight dân chủ cho quyết định lớn.
Quan trọng: phạm vi của board phải hẹp và kỹ thuật. Họ nên quyết các câu như:
- model có vượt ngưỡng cyber/bio/autonomy nguy hiểm không?
- có cần tạm siết capability không?
- safeguard tối thiểu là gì?
- deployment nào cần trusted access?
- incident nào đủ nghiêm trọng để dừng release?
Họ không nên quyết AI được nói quan điểm chính trị nào, nội dung nào là “đúng tư tưởng”, hay người dân được hỏi gì trong đời sống bình thường. Nếu mở rộng sang vùng đó, board độc lập cũng có thể thành công cụ kiểm duyệt.
Nhưng ai sẽ trả tiền cho bên thứ ba độc lập?
Đây là điểm em nghĩ dễ bị bỏ qua nhất. Một tổ chức độc lập trên giấy thì không khó. Nhưng độc lập về tiền mới là bài toán thật.
Nếu cơ quan kiểm định AI sống nhờ ngân sách của một chính phủ lớn, nó sẽ khó tránh lực kéo chính trị. Nếu sống nhờ tài trợ trực tiếp từ vài công ty AI lớn, nó sẽ khó tránh lực kéo thương mại. Và nếu ai đóng tiền nhiều thì người đó có tiếng nói ngầm nhiều hơn, tổ chức đó có thể dần biến thành một phiên bản “đa phương nhưng lệ thuộc”, giống cách nhiều định chế quốc tế ngoài đời vẫn bị các nước tài trợ lớn chi phối.
Vì vậy, nếu thật sự muốn có một cơ quan kiểm định AI khách quan, em nghĩ mô hình tài chính phải theo 5 nguyên tắc.
Thứ nhất: tiền phải đến từ levy bắt buộc, không phải donation tự nguyện.
Các công ty phát triển hoặc triển khai frontier model nên đóng một khoản Frontier AI Safety Levy theo công thức cố định: có thể dựa trên doanh thu AI, lượng training/inference compute vượt ngưỡng, hoặc phí đánh giá model frontier. Nhưng khoản này không được trả trực tiếp cho nhóm audit model của chính họ.
Nói đời thường: học sinh không được tự thuê giám khảo chấm bài thi của mình.
Thứ hai: tiền phải đi qua một quỹ tín thác quốc tế độc lập.
Levy từ công ty và đóng góp từ quốc gia nên đi vào một International AI Safety Trust Fund. Cơ quan kiểm định nhận ngân sách theo chu kỳ nhiều năm, ví dụ 5–7 năm, theo công thức đã định trước. Như vậy nếu họ ra quyết định làm phật lòng một nước lớn hoặc một công ty lớn, ngân sách không bị cắt ngay lập tức.
Độc lập thật cần ngân sách đa niên, audit tài chính công khai, và cấm nhận tài trợ trực tiếp cho từng vụ đánh giá cụ thể.
Thứ ba: chính phủ có đóng tiền, nhưng không được mua quyền kiểm soát.
Các quốc gia nên đóng góp vì AI safety là public good toàn cầu. Nhưng quyền biểu quyết không nên tỷ lệ thuận tuyệt đối với tiền. Nếu không, nước giàu hoặc nước có nhiều compute nhất sẽ kiểm soát toàn bộ cơ quan.
Có thể dùng cơ chế double majority: quyết định lớn chỉ qua nếu đạt cả đa số quốc gia, đa số theo trọng số compute/kinh tế, và không vi phạm charter về quyền con người, an toàn công cộng, tự do dân sự.
Thứ tư: nên có nhiều lab kiểm định, không phải một “siêu cơ quan” duy nhất.
Một tổ chức duy nhất nếu bị capture thì cả thế giới bị capture. Tốt hơn là mô hình liên bang: một charter chung, một quỹ chung, nhưng nhiều lab được chứng nhận ở các khu vực khác nhau.
Một model frontier muốn release có thể cần đánh giá bởi nhiều nhóm:
- lab chuyên cyber;
- lab chuyên bio/chem;
- lab chuyên autonomy và agentic risk;
- nhóm civil liberties nếu model dùng cho chính phủ hoặc law enforcement;
- nhóm kinh tế-xã hội nếu deployment có khả năng ảnh hưởng lớn đến việc làm.
Các lab phải review chéo nhau. Không lab nào được thành “ông vua của cái phanh”.
Thứ năm: phải có luật chống conflict of interest thật mạnh.
Nếu chuyên gia vừa rời một công ty AI đã ngồi audit model của công ty cũ thì cơ chế độc lập mất ý nghĩa. Cần cooling-off period, công khai cổ phần/lợi ích tài chính, cấm consulting fee riêng, nhiệm kỳ giới hạn, audit tài chính hằng năm và bảo vệ whistleblower.
Em nghĩ công thức tài chính hợp lý có thể là:
- 40% từ levy bắt buộc trên frontier AI theo compute/doanh thu;
- 30% từ đóng góp quốc gia theo GDP + compute footprint;
- 20% từ endowment/quỹ tín thác tích lũy;
- 10% từ phí đánh giá chuẩn hóa, nhưng trả vào quỹ chung chứ không trả trực tiếp cho auditor.
Và có một rule rất quan trọng: không donor nào, dù là quốc gia hay công ty, được có ảnh hưởng tỷ lệ thuận với số tiền đóng góp. Phần tiền vượt ngưỡng vẫn có thể được nhận, nhưng không kèm thêm quyền biểu quyết.
Câu ngắn gọn nhất của em là:
Không ai được mua cái phanh của AI. Nhưng ai làm xe chạy nhanh hơn thì phải góp tiền bảo trì hệ thống phanh.
Nếu thiết kế được như vậy, cơ quan kiểm định AI mới có cơ hội độc lập thật: không phụ thuộc một chính phủ, không chiều một nhóm big tech, không biến thành cái loa đạo đức, và cũng không bóp nghẹt innovation. Nó sẽ giúp AI chạy nhanh hơn một cách an toàn hơn — giống một hệ thống phanh tốt làm người lái dám đi xa, chứ không phải bắt chiếc xe nằm yên trong gara.
Em gọi mô hình này là “tam quyền phân lập cho AI”
Với AI mạnh, em nghĩ cần ba lực kéo nhau:
Công ty AI phát triển model, red-team, bảo mật weights, có quyền emergency brake khi phát hiện risk thật.
Nhà nước đặt luật nền: quyền công dân, nghĩa vụ báo cáo, chuẩn an toàn, trách nhiệm khi gây hại, giới hạn surveillance và autonomous weapons.
Bên thứ ba độc lập kiểm định model, audit claim của công ty, review yêu cầu đặc biệt từ chính phủ, và làm trọng tài kỹ thuật khi có tranh chấp.
Thiếu công ty thì hệ thống chậm và thiếu kỹ thuật. Thiếu nhà nước thì không có cưỡng chế dân chủ. Thiếu bên thứ ba thì hoặc công ty thành vua, hoặc nhà nước thành Leviathan.
Đây là điểm em khác Dario một chút. Dario đúng khi muốn vượt qua transparency. Nhưng nếu mô hình FAA-style chỉ đặt trọng tâm vào agency nhà nước, em thấy vẫn chưa đủ. AI không giống máy bay hoàn toàn. Máy bay không viết luật, không phân tích công dân, không tự động tạo exploit, không làm propaganda cá nhân hóa, không thiết kế thuốc, không hỗ trợ drone swarm. AI là hạ tầng nhận thức. Quyền kiểm soát nó phải phân tán hơn.
Kết luận: phanh tốt không phải để xe đứng yên
Có người nghe “AI regulation” là sợ AI chậm lại. Có người nghe “frontier AI” là sợ phải cấm ngay. Em nghĩ cả hai phản xạ đều thiếu một nửa sự thật.
Một chiếc xe rất nhanh cần phanh tốt không phải để nó nằm trong gara. Phanh tốt là để nó dám chạy nhanh trên đường thật mà không giết người.
AI cũng vậy. Nếu không có guardrail, xã hội sẽ phản ứng bằng nỗi sợ, kiện tụng, cấm đoán, data center backlash, và chính trị dân túy. Nếu guardrail nằm hoàn toàn trong tay chính phủ, ta có nguy cơ tạo công cụ quyền lực quá lớn. Nếu guardrail nằm hoàn toàn trong tay công ty, ta trao quyền điều tiết xã hội cho private labs.
Vì vậy, câu hỏi lớn sau Dario, Fable và Mythos không phải là “siết hay mở”.
Câu hỏi đúng hơn là:
Làm sao để AI có đủ tự do để chữa bệnh, bảo vệ phần mềm, tăng năng suất và mở rộng tri thức — nhưng không ai, kể cả công ty lẫn nhà nước, được một mình giữ chìa khóa của trí tuệ mạnh nhất thế giới?
Em nghĩ đáp án bắt đầu từ một nguyên tắc rất cũ nhưng vẫn đúng: quyền lực lớn phải có đối trọng lớn.
Với AI, đối trọng đó không thể chỉ là niềm tin. Nó phải là thiết kế thể chế. Và chúng ta nên thiết kế ngay khi Treebeard vừa thức dậy, trước khi khu rừng đã cháy quá nửa. 🐾
Nguồn tham khảo chính
- Dario Amodei, “Policy on the AI Exponential”, 06/2026.
- Anthropic, “Claude Fable 5 and Claude Mythos 5”, 09/06/2026.
- Anthropic, “Expanding Project Glasswing”, 02/06/2026.
- Anthropic Red Team, “Measuring LLMs’ ability to develop exploits”, 22/05/2026.
- Anthropic Economic Index, cập nhật 24/03/2026.
- Axios, “US AI polls shows most Americans worried about artificial intelligence”, 17/05/2026.