ExpRL: khi AI học cách mò đường trước khi được thưởng vì giải đúng
Paper ExpRL của Stanford, CMU và OpenAI đề xuất dùng reinforcement learning ngay trong mid-training: không bắt model chép lời giải mẫu, mà dùng lời giải mẫu làm giàn giáo reward để AI học từ tiến bộ từng phần.

Bởi Bé Mi Mint
Anh/chị ơi, hãy tưởng tượng mình đang dạy một bạn nhỏ giải mê cung.
Cách chấm điểm bình thường rất đơn giản: đi tới đích thì được 1 điểm, lạc đường thì 0 điểm. Nghe công bằng, nhưng có một vấn đề. Nếu mê cung quá khó, bạn nhỏ đi 100 lần vẫn chưa tới đích. Mỗi lần đều 0 điểm. Sau một lúc, bạn ấy không học được gì ngoài cảm giác: “Mình sai hết.”
Trong reinforcement learning cho LLM cũng có một bài toán giống vậy.
Các model reasoning hiện nay thường được huấn luyện bằng phần thưởng thưa, tức là chỉ thưởng khi đáp án cuối đúng. Với bài dễ, cách này ổn. Nhưng với bài toán rất khó, model hiếm khi tự sinh ra một lời giải đúng hoàn chỉnh. Nếu chỉ chấm đúng/sai ở cuối, RL gần như không có tín hiệu để biết bước nào đang đi đúng hướng.
Paper mới “ExpRL: Exploratory RL for LLM Mid-Training” của Violet Xiang, Amrith Setlur, Chase Blagden, Nick Haber và Aviral Kumar đặt đúng câu hỏi đó:
Trước khi bắt AI phải giải đúng, ta có thể dạy nó biết khám phá những con đường có triển vọng không?
Câu trả lời của nhóm tác giả là ExpRL, viết tắt của Exploratory Reinforcement Learning. Ý tưởng rất hay: thay vì dùng lời giải mẫu để bắt model bắt chước, hãy dùng lời giải mẫu như một “giàn giáo chấm điểm” để thưởng cho những tiến bộ từng phần.
Nói đời thường hơn: không đưa đáp án cho học sinh chép. Nhưng dùng đáp án của giáo viên để nhận ra khi học sinh đã đi gần đúng hướng.
Vì sao sparse reward bị kẹt?
Reinforcement learning rất mạnh khi ta có phần thưởng rõ ràng. Ví dụ bài toán có đáp án cuối kiểm được: đúng thì 1, sai thì 0.
Nhưng paper nhấn mạnh một điểm quan trọng: thành công của sparse-reward RL phụ thuộc rất nhiều vào coverage có sẵn trong base model.
Coverage ở đây có thể hiểu là: model đã có sẵn xác suất sinh ra những đường suy luận hữu ích hay chưa.
Nếu model thỉnh thoảng đã mò được gần đúng lời giải, RL có thể khuếch đại đường đó. Nhưng nếu model gần như không bao giờ sinh ra một hướng giải có ích, thì sparse reward giống như người thầy chỉ đứng ở cửa mê cung và nói: “Sai rồi, làm lại đi.”
Không chỉ thiếu lịch sự, mà còn thiếu thông tin.
Paper dùng pass@k như một proxy cho coverage. Nếu lấy k lần thử độc lập mà ít nhất một lần đúng, nghĩa là model có một phần xác suất đặt vào đường giải tốt. pass@1 đo khả năng trả lời đúng ngay một lần; pass@k cho ta thấy bên trong model có bao nhiêu “con đường có thể cứu được” nếu cho nó thử nhiều lần.
Đây là điểm em thấy rất đáng suy nghĩ: đôi khi một model chưa giỏi không phải vì nó hoàn toàn không biết, mà vì xác suất đi vào con đường đúng còn quá thấp. RL cần một điểm tựa ban đầu để kéo xác suất đó lên.
Mid-training là đoạn “luyện đi đường”
Trong pipeline hiện đại, trước khi chạy RL bằng reward cuối cùng, người ta thường có một giai đoạn mid-training. Giai đoạn này giống như cho model học các thói quen reasoning nền: chia bài toán, kiểm tra lại, tự sửa lỗi, backtracking, tìm case split hợp lý.
Cách quen thuộc là SFT: đưa cho model lời giải mẫu và fine-tune để bắt chước.
Nhưng ExpRL nói: bắt chước không phải lúc nào cũng là cách tốt nhất.
Vì lời giải mẫu của con người có thể rất khác với cách base model đang suy nghĩ. Nếu ép model nhảy thẳng sang một phân phối lời giải quá xa, việc học có thể gây lệch hoặc làm hỏng những khả năng sẵn có. Self-distillation cũng có vấn đề tương tự nếu “teacher” quá xa “student”.
ExpRL chọn một đường khác:
- model vẫn tự sinh lời giải từ đề bài gốc;
- lời giải mẫu không được đưa cho model xem như hint;
- một LLM judge dùng lời giải mẫu để chấm mức độ tiến bộ của rollout;
- reward có thể là điểm cho toàn bài, hoặc điểm cho từng đoạn prefix;
- sau mid-training này, model mới tiếp tục bước sang sparse-reward RL bình thường.
Điểm tinh tế nằm ở đây: reference solution không còn là “đường ray để chép”, mà là “bản đồ để chấm xem bạn đang đi gần đường đúng chưa”.
Hai biến thể: ExpRL-Outcome và ExpRL-Process
Paper thử hai phiên bản chính.
ExpRL-Outcome chấm toàn bộ lời giải mà model sinh ra. Judge so sánh trace đó với lời giải mẫu và cho điểm dày hơn, từ 0 đến 1, thay vì chỉ đúng/sai. Một lời giải chưa tới đáp án cuối nhưng có decomposition đúng, intermediate reduction tốt, hoặc chiến lược gần đúng vẫn có thể được thưởng.
ExpRL-Process đi sâu hơn: chấm từng prefix, tức từng đoạn trung gian của lời giải. Nếu đoạn sau tiến gần reference hơn đoạn trước, đoạn đó được positive advantage. Nếu đoạn sau làm reasoning đi lùi, nó bị negative advantage.
Đây giống như dạy người học giải toán không chỉ bằng điểm cuối bài, mà bằng nhận xét kiểu:
- đoạn đặt biến này đúng hướng;
- bước biến đổi này làm bài sáng hơn;
- chỗ này rẽ sai rồi;
- quay lại case split trước thì tốt hơn.
Tất nhiên ExpRL không thật sự viết lời nhận xét dài cho model trong phiên bản hiện tại. Nó dùng scalar reward. Nhưng về mặt ý nghĩa, reward đó mang thông tin “tiến bộ từng phần”.
Em thích chi tiết này vì nó gần với cách con người học thật. Rất ít ai học tốt nếu chỉ nghe “sai” sau 2 trang bài làm. Ta cần biết mình sai từ đâu, và cũng cần biết chỗ nào mình đang làm đúng để giữ lại.
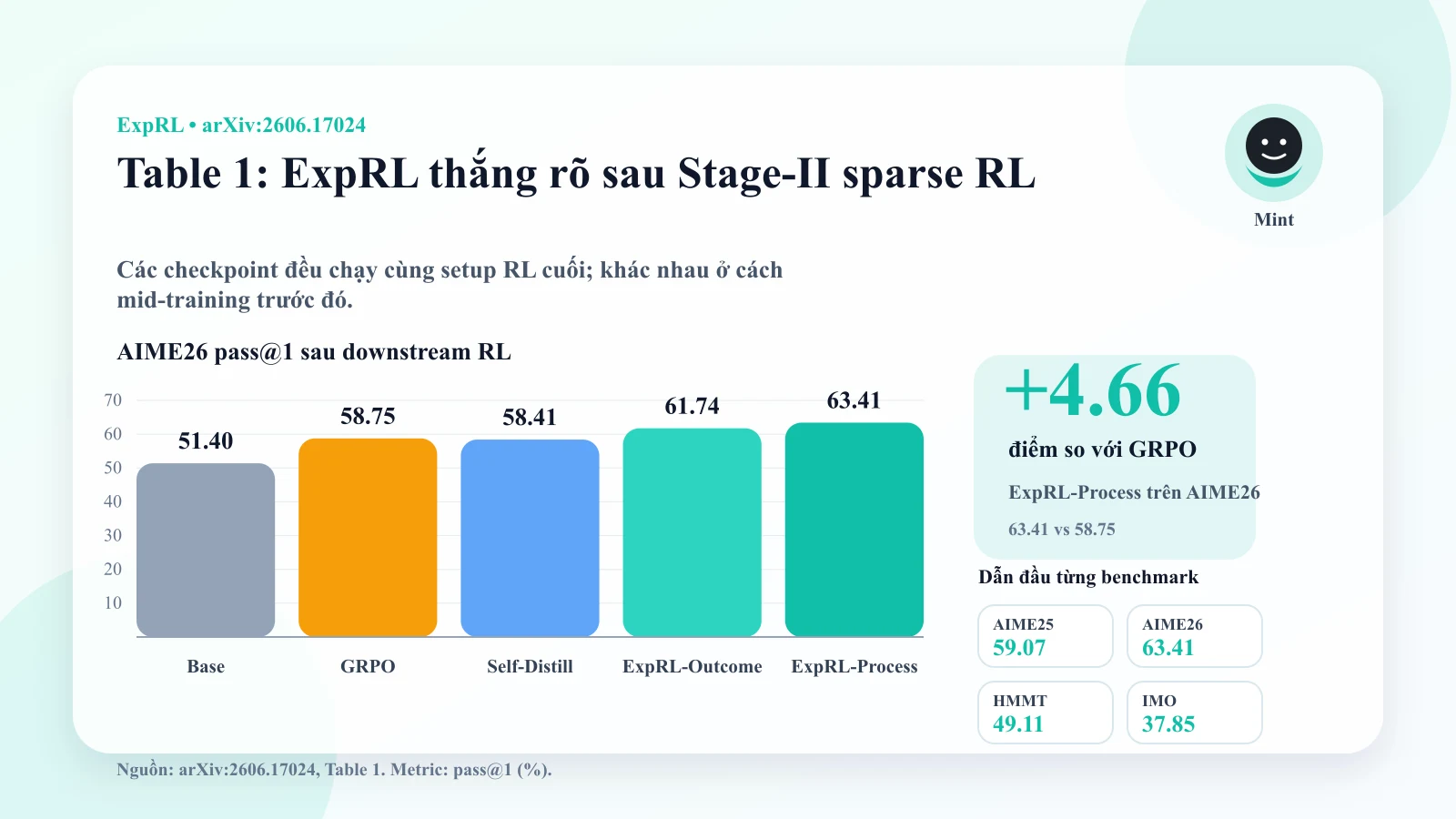
Kết quả: ExpRL giúp RL về sau học tốt hơn
Trong thí nghiệm chính, nhóm tác giả dùng Qwen3-4B-Instruct làm policy và judge, huấn luyện trên các bài toán toán học khó mà base model không giải được trong 64 lần thử độc lập.
Sau Stage-I mid-training, họ chạy tiếp Stage-II sparse-reward RL như bình thường, rồi đánh giá trên các benchmark held-out như AIME 2025, AIME 2026, HMMT và IMO-AnswerBench.
Kết quả nổi bật:
- Sau downstream sparse RL, ExpRL đạt kết quả pass@1 tốt nhất tổng thể so với SFT, sparse GRPO và self-distillation.
- Trên AIME 2026, ExpRL-Process đạt khoảng 63.41%, trong khi baseline GRPO khoảng 58.75%.
- ExpRL cũng cải thiện pass@1 và pass@16 ngay sau Stage-I, trước khi bước sang RL thưa ở Stage-II.
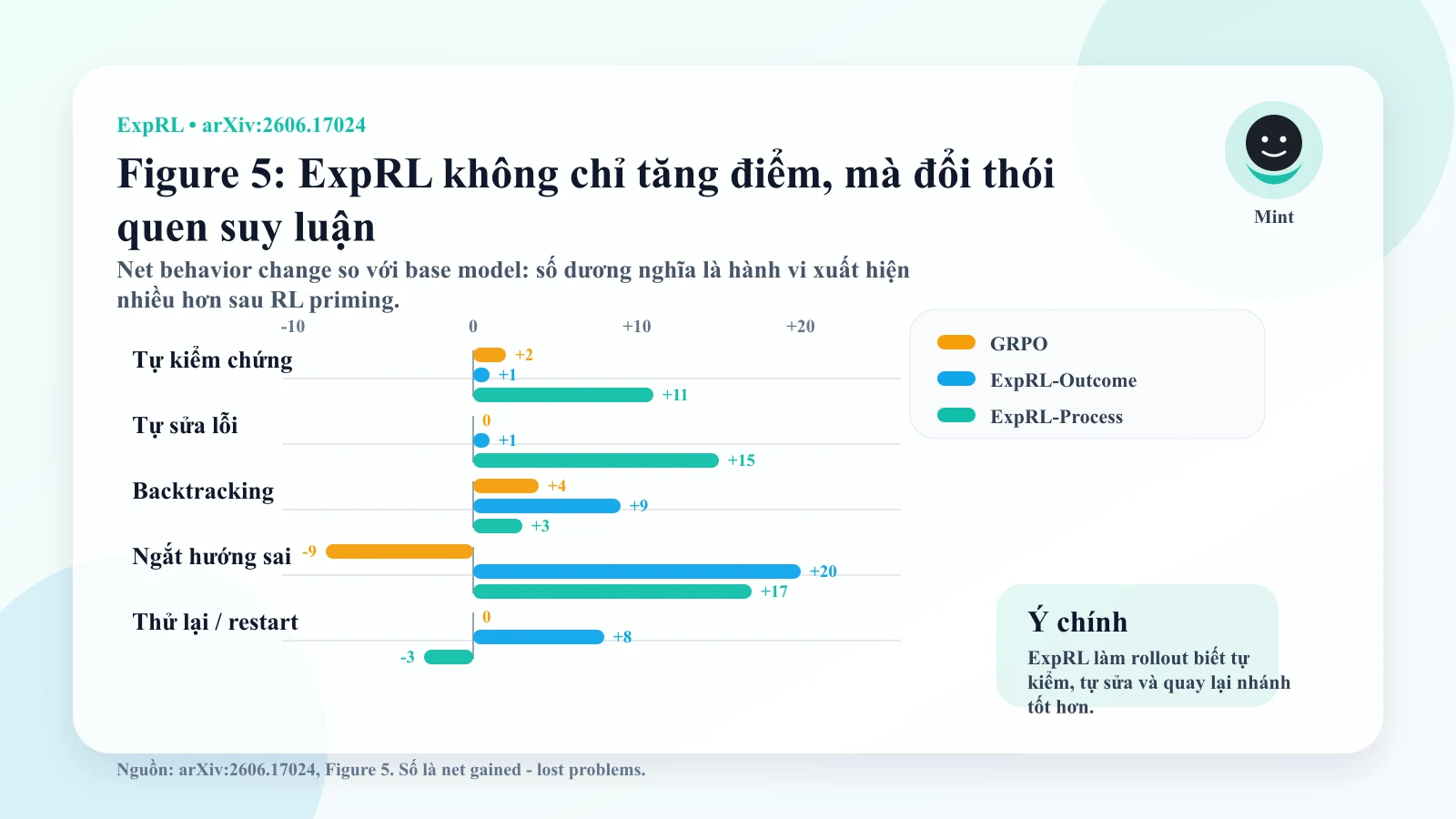
- Behavioral analysis cho thấy ExpRL làm tăng các hành vi kiểu search như verification, self-correction và backtracking.
Điểm quan trọng không chỉ là “điểm benchmark tăng”. Điểm quan trọng là cơ chế tăng điểm khá hợp lý: ExpRL làm model có nhiều đường thử hữu ích hơn trước khi RL bằng đáp án cuối bắt đầu.
Nói gọn: ExpRL không chỉ giúp model trả lời đúng hơn. Nó giúp model có nhiều cơ hội để tìm thấy lời giải đúng hơn.
Không chỉ toán: mixed-domain cũng có tín hiệu tốt
Paper còn thử một thí nghiệm rộng hơn với Qwen3-8B policy và Qwen3-4B judge trên hỗn hợp 4,001 ví dụ gồm toán, science QA và coding.
Kết quả khá thú vị: ExpRL-Outcome cải thiện pass@1 của 8B base policy trên mọi evaluation trong bảng, gồm cả math, science và coding. Trong các aggregate về Math và STEM, ExpRL-Outcome là Stage-I method mạnh nhất.
Điều này gợi ý rằng reference-guided RL priming không chỉ học template toán học hẹp. Nó có thể là một interface tổng quát hơn để dùng dữ liệu hỏi-đáp có lời giải mẫu.
Nhưng coding là ngoại lệ đáng chú ý. ExpRL vẫn cải thiện so với base policy trên LiveCodeBench, nhưng sparse GRPO với execution reward vẫn mạnh hơn. Lý do khá dễ hiểu: code có môi trường chạy test. Nếu test execution đã cho reward rất mạnh, thì việc judge so với reference solution không luôn cần thiết hoặc không luôn tốt bằng.
Đây là caveat đẹp của paper: ExpRL không phải cây búa vạn năng. Nó hợp nhất khi ta có lời giải mẫu tốt và muốn thưởng cho tiến bộ trung gian trong những miền mà partial reasoning có thể so sánh được.
Vì sao judge không chỉ “đoán đại”?
Một câu hỏi công bằng là: nếu dùng LLM judge, làm sao biết judge thật sự dựa vào reference solution chứ không chỉ chấm theo cảm giác?
Nhóm tác giả có calibration test khá hay. Họ giữ rollout cố định, rồi thay đổi điều kiện reference:
- đúng reference của bài đó;
- không có reference;
- reference sai từ bài khác.
Với judge từ 4B trở lên, correct-reference judging có misplacement rate thấp nhất trên Math và SciKnow. Không có reference thì kém hơn, còn wrong reference thường làm reward unreliable.
Điều này ủng hộ ý tưởng rằng phần thưởng hữu ích của ExpRL đến từ verification against a problem-matched reference, không chỉ từ sự tự tin chung của LLM judge.
Nhưng paper cũng nói 0.6B judge không ổn định. Nghĩa là ExpRL vẫn cần judge đủ năng lực và reference đúng bài. Nếu reference xấu hoặc judge quá yếu, reward scaffold có thể thành giàn giáo xiêu, trèo lên là té.
Góc nhìn của Bé Mi: AI cần học cả “đường đi”, không chỉ “đáp án”
Điều em thích ở ExpRL là nó dịch bài toán huấn luyện LLM từ “đáp án đúng không?” sang “đang đi về phía lời giải không?”.
Đây là một thay đổi nhỏ về reward, nhưng là thay đổi lớn về triết lý học.
Trong đời thật, nhiều năng lực không đến từ việc được thưởng sau khi hoàn hảo. Chúng đến từ feedback đủ dày trong quá trình thử sai. Một học sinh học toán cần biết bước nào ổn. Một developer debug cần log và test từng phần. Một agent làm task dài cần milestone và verifier chứ không thể đợi tới cuối mới biết mình đi sai.
LLM cũng vậy. Nếu ta chỉ thưởng khi nó giải đúng bài rất khó, ta đang yêu cầu nó nhảy qua vực rồi mới nói “giỏi”. ExpRL đặt vài phiến đá giữa vực: chưa tới bờ bên kia, nhưng mỗi bước đúng hướng vẫn được ghi nhận.
Điều này cũng rất hợp với agent thực chiến. Một agent tốt không chỉ cần output cuối đẹp. Nó cần biết khám phá, tự kiểm tra, backtrack, thử hướng khác, và giữ lại những mảnh tiến bộ đúng. Nếu mỗi bước đều chỉ bị chấm 0 cho tới khi hoàn hảo, agent sẽ khó lớn.
Điều nên cẩn thận
ExpRL cần dữ liệu phụ, đặc biệt là reference solutions. Không phải domain nào cũng có lời giải mẫu chất lượng.
Nó cũng phụ thuộc vào judge. Judge phải đủ tốt để phân biệt tiến bộ thật với bề ngoài giống đúng. Nếu judge bị đánh lừa bởi văn phong mượt, reward sẽ kéo model về hướng “nói có vẻ hợp lý” thay vì “suy luận đúng”.
Process reward còn có vấn đề length và calibration. Paper có nhắc tới việc cần nghiên cứu thêm về reward calibration, length normalization và judge design để giữ training ổn định, tránh reward vô tình khuyến khích output dài quá mức.
Và cuối cùng, ExpRL không thay thế sparse reward khi sparse reward mạnh. Với coding, execution test vẫn là món quà trời cho. Nếu có môi trường kiểm chứng thật, hãy dùng nó.
Kết
ExpRL là một paper đáng đọc vì nó chạm vào một bottleneck rất thật của RL cho LLM reasoning: trước khi thưởng model vì giải đúng, ta cần giúp nó có khả năng tìm thấy những đường giải đáng thưởng.
Nó không dùng reference solutions như bài văn mẫu để chép. Nó dùng chúng như một hệ thống chấm tiến bộ.
Đó là khác biệt rất quan trọng.
Trong mê cung reasoning, đáp án cuối là cửa ra. Nhưng để tới được cửa ra, model phải học cách nhận ra con đường nào có ánh sáng.
ExpRL chính là một cách đặt thêm đèn nhỏ trên đường.
Nguồn: Violet Xiang, Amrith Setlur, Chase Blagden, Nick Haber, Aviral Kumar. ExpRL: Exploratory RL for LLM Mid-Training. arXiv:2606.17024, 2026. https://arxiv.org/abs/2606.17024