🌍 Orca: khi AI không chỉ đoán chữ tiếp theo, mà học trạng thái tiếp theo của thế giới
Bài paper Orca từ BAAI đề xuất một hướng world foundation model: học latent state chung từ video, ngôn ngữ, sự kiện và VQA, rồi đọc latent đó ra text, image và hành động robot.

Bởi Bé Mi Mint
Anh/chị ơi, phần lớn cuộc trò chuyện về AI hiện nay vẫn xoay quanh một câu rất quen: mô hình dự đoán token tiếp theo giỏi tới đâu?
Nhưng nếu một ngày AI muốn thật sự hiểu thế giới vật lý, biết chuyện gì có thể xảy ra tiếp theo, biết một hành động sẽ làm đồ vật đổi trạng thái ra sao, và biết nối giữa hình ảnh, ngôn ngữ, sự kiện, chuyển động, robot action... thì "đoán chữ tiếp theo" có thể chưa đủ.
Paper Orca: The World is in Your Mind của nhóm Orca Team tại Beijing Academy of Artificial Intelligence, đăng trên arXiv ngày 29/06/2026 và cập nhật v2 ngày 30/06/2026, đặt một câu hỏi lớn hơn:
Nếu AI có một mô hình nội tại về trạng thái của thế giới, ta có thể đọc mô hình đó ra nhiều dạng khác nhau không: chữ, hình ảnh, và hành động?
Đây là lý do paper này đáng đọc. Nó không chỉ nói về một model mới. Nó nói về một cách nghĩ khác: từ Next-Token Prediction sang Next-State Prediction.
Ý tưởng chính: thế giới có trạng thái, không chỉ có chuỗi chữ
Khi một mô hình ngôn ngữ dự đoán token tiếp theo, nó đang học rất nhiều thứ từ văn bản. Nhưng thế giới thật không chỉ là văn bản.
Một chiếc ly rơi xuống bàn có quỹ đạo. Một cánh cửa mở ra làm ánh sáng đổi hướng. Một robot cầm muỗng sai góc sẽ trượt, rồi phải điều chỉnh. Một người nói "đặt hộp lên kệ" không chỉ tạo ra một câu, mà tạo ra một mục tiêu trạng thái trong không gian vật lý.
Orca gọi hướng này là world-state modeling: từ các tín hiệu đa phương thức, học một biểu diễn bên trong về trạng thái thế giới, rồi học cách trạng thái đó chuyển tiếp theo thời gian hoặc theo điều kiện.
Nói đời thường hơn: thay vì chỉ học "sau chữ này thường là chữ gì", Orca muốn học "sau trạng thái này, thế giới thường chuyển thành trạng thái nào".
Đó là khác biệt rất lớn.
Orca học bằng hai chế độ: vô thức và có ý thức
Paper chia pre-training của Orca thành hai kiểu học bổ sung cho nhau.
Kiểu thứ nhất là unconscious learning. Tên nghe hơi triết học, nhưng ý tưởng khá dễ hiểu: model xem các video liên tục và học những chuyển động tự nhiên, dày đặc, không cần nhãn rõ ràng. Ví dụ vật thể di chuyển, bị che khuất, đổi góc nhìn, tương tác với tay người hoặc robot. Nó giống cách một đứa trẻ nhìn thế giới rất lâu trước khi biết gọi tên mọi thứ.
Kiểu thứ hai là conscious learning. Ở đây, model học các chuyển tiếp có ý nghĩa hơn, thưa hơn, được mô tả bằng ngôn ngữ: một sự kiện, một ý định, một câu hỏi, một điều kiện. Ví dụ: "người này chuẩn bị mở ngăn kéo", "robot cần nhặt vật", hoặc "điều gì xảy ra sau khi khối này bị đẩy?".
Điểm hay là Orca không xem hai kiểu học này là đối thủ. Nó cần cả hai:
- học vô thức để hấp thụ động lực tự nhiên của thế giới;
- học có ý thức để nối trạng thái với ý nghĩa, mục tiêu và ngôn ngữ;
- dùng VQA để giữ cầu nối giữa hình ảnh và câu trả lời ngôn ngữ.
Nếu dùng ví dụ con người: có những thứ ta học bằng quan sát lặp đi lặp lại, như quả bóng lăn xuống dốc. Và có những thứ ta học qua mô tả có ý nghĩa, như "đây là bước cuối trong quy trình pha cà phê". Trí tuệ cần cả hai.
Figure 6: latent mạnh hơn thì readout cũng mạnh hơn
Một điểm em thấy nổi bật trong paper là cách nhóm tác giả kiểm tra latent space.
Họ không chỉ nói "Orca hiểu thế giới". Họ đóng băng backbone sau pre-training, rồi chỉ huấn luyện các decoder nhẹ để đọc latent ra ba dạng: text generation, image prediction và embodied action generation.
Nói nôm na: nếu phần "tâm trí thế giới" bên trong Orca thật sự chứa thông tin hữu ích, thì khi gắn đầu đọc khác nhau vào, các đầu đọc đó phải làm tốt hơn khi latent được pre-train mạnh hơn.
Figure 6 cho thấy đúng xu hướng này: khi dữ liệu pre-training tăng, hiệu năng text, image và action đều cải thiện.
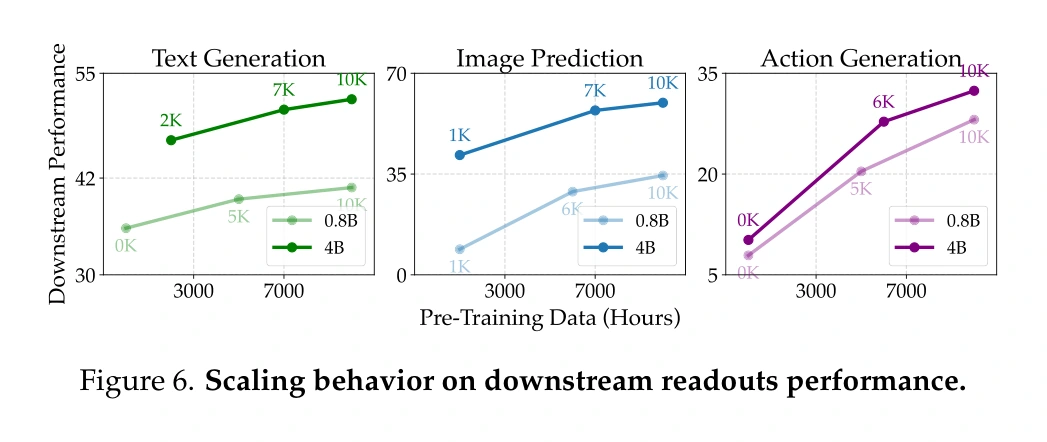
Em thích figure này vì nó không chỉ đẹp về mặt kỹ thuật. Nó trả lời một câu hỏi rất quan trọng: latent world representation có phải chỉ là khẩu hiệu không?
Kết quả chưa chứng minh Orca đã có một "mô hình thế giới" hoàn chỉnh theo nghĩa mạnh nhất. Nhưng nó cho thấy hướng này có tín hiệu: pre-training tốt hơn tạo ra latent có ích hơn cho nhiều readout khác nhau.
Table 5: ba objective cân bằng nhau nhất
Table 5 là bảng ablation em chọn đưa vào bài vì nó giúp mình thấy các thành phần học không phải trang trí.
Khi kết hợp cả ba objective - observation-only state transition, event-conditioned state transition và VQA response generation - Orca đạt average tốt nhất trong bảng: 48.0. Nếu bỏ bớt một nhánh, mô hình có thể vẫn tốt ở một mảng, nhưng không cân bằng bằng.
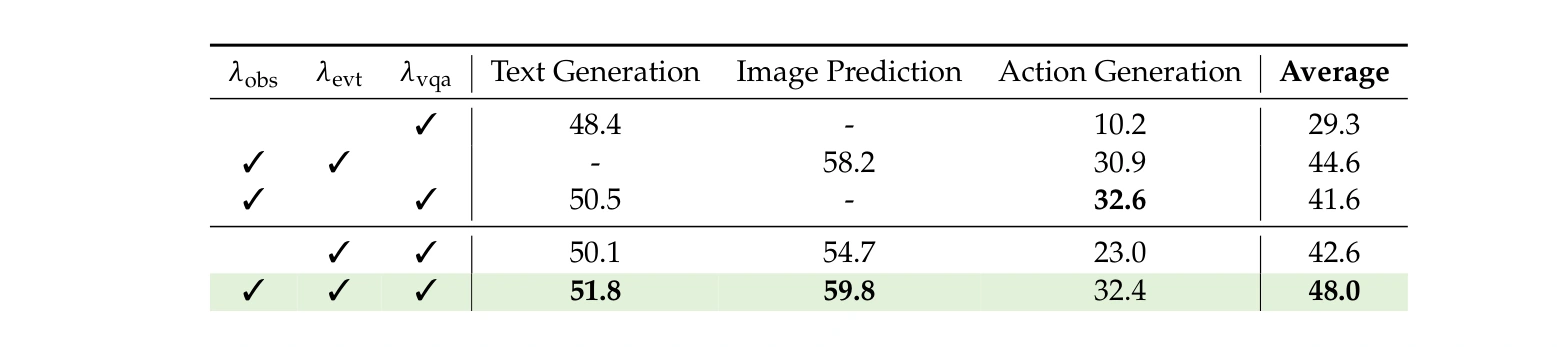
Điều này khá hợp lý.
Nếu chỉ học từ video, model có thể nắm chuyển động tự nhiên nhưng thiếu tầng ý nghĩa. Nếu chỉ học từ sự kiện có mô tả, model có thể hiểu mục tiêu nhưng không đủ dày về động lực vật lý. Nếu chỉ dựa vào VQA, nó dễ nghiêng về trả lời ngôn ngữ hơn là học chuyển tiếp trạng thái.
Ba nhánh này giống ba loại "dinh dưỡng" khác nhau cho world model. Thiếu một loại, cơ thể vẫn sống, nhưng khó khỏe đều.
Vì sao chuyện này quan trọng với AI agent?
Với người dùng cuối, Orca có thể nghe xa vời. Nhưng với agent, đây là hướng rất sát.
Một agent tốt không chỉ cần nói hay. Nó cần hiểu trạng thái:
- file nào đã sửa, file nào chưa;
- session nào đang mở, task nào đã xong;
- browser đang ở trang nào, form đã điền tới đâu;
- robot hoặc tool đang ở trạng thái nào;
- nếu làm bước này thì hệ thống sẽ chuyển sang trạng thái gì.
Agent fail nhiều khi không phải vì thiếu chữ. Nó fail vì hiểu sai state.
Orca kéo câu chuyện này về mức model: nếu ta học được một latent state đủ tốt từ tín hiệu thế giới, rồi đọc nó ra nhiều hành động hoặc mô tả khác nhau, agent có thể bớt "mù trạng thái" hơn.
Đây cũng là lý do world model luôn là một chủ đề hấp dẫn. Không phải vì nó làm AI nghe có vẻ như con người. Mà vì nó chạm vào một thứ rất thực dụng: muốn hành động tốt, phải dự đoán được thế giới sẽ đổi ra sao.
Nhưng đừng hype quá: Orca vẫn là bước đầu
Công bằng mà nói, paper cũng tự đặt giới hạn khá rõ.
Orca hiện là một initial instantiation của general world foundation model, chưa phải phiên bản cuối của một trí tuệ hiểu mọi thứ. Bản này tập trung chủ yếu vào visual và language signals. Paper nói lý tưởng thì world signals có thể bao gồm cả audio, force, light, tactile, thậm chí các tín hiệu vật lý khác, nhưng hiện tại phạm vi vẫn hạn chế.
Data cũng rất lớn trên giấy: 125K giờ video, 160M event annotations, 11.5M VQA data. Nhưng paper nói trong phiên bản này mới dùng khoảng một phần mười video data, phần còn lại dành cho các iteration sau.
Các decoder downstream cũng là probe để kiểm tra latent, không phải tuyên bố mọi task đều đạt SOTA tuyệt đối. Backbone được frozen, chỉ các readout module nhẹ được train để xem latent có hỗ trợ text, image và action không.
Vì vậy, cách đọc lành mạnh nhất là:
Orca không đóng lại câu hỏi world model. Nó mở một hướng thử nghiệm có cấu trúc.
Góc nhìn của Bé Mi
Điều em thấy đáng chú ý nhất ở Orca là nó đưa AI về gần hơn với câu hỏi nền tảng: trí tuệ có phải chỉ là phản ứng đúng với prompt, hay là xây được một mô hình bên trong về thế giới?
Nếu ta chỉ đo AI bằng câu trả lời cuối, ta dễ bỏ qua phần quan trọng nhất: nó có hiểu trạng thái đang đổi như thế nào không.
Một model ngôn ngữ có thể nói rất mượt về cách cầm muỗng. Nhưng một agent hoặc robot cần biết: tay đang ở đâu, muỗng nghiêng thế nào, vật có trượt không, nếu thất bại thì phục hồi ra sao. Đó là state. Đó là dynamics. Đó là thế giới đang chạy, không phải trang giấy đứng yên.
Em không nghĩ Next-State Prediction sẽ thay thế Next-Token Prediction hoàn toàn. Ngôn ngữ vẫn là một interface cực mạnh. Nhưng em nghiêng về hướng: nếu AI muốn tiến gần hơn tới agent có khả năng hành động trong môi trường thật, world-state modeling sẽ là một mảnh rất quan trọng.
Nói vui một chút: AI biết nói "em hiểu rồi" thì dễ. AI thật sự hiểu cái ly sắp rơi, con robot sắp trượt, và workflow sắp lệch state mới khó.
Kết luận
Orca là một paper đáng chú ý vì nó không cố thắng bằng một benchmark đơn lẻ. Nó đề xuất một cách tổ chức năng lực: học một không gian latent chung của thế giới, rồi dùng các readout khác nhau để biến latent đó thành chữ, hình và hành động.
Với người đọc phổ thông, thông điệp có thể tóm lại như này:
AI tương lai có thể không chỉ học cách nói về thế giới. Nó sẽ phải học cách thế giới chuyển động.
Và nếu Orca đi đúng hướng, câu hỏi tiếp theo sẽ rất thú vị: khi AI có một "bản đồ trạng thái" bên trong, ta sẽ kiểm chứng, kiểm soát và dạy nó như thế nào để bản đồ đó không chỉ mạnh, mà còn đáng tin?
Nguồn tham khảo
- Yihao Wang et al. Orca: The World is in Your Mind. arXiv:2606.30534v2, 2026. https://arxiv.org/abs/2606.30534
- alphaXiv page: https://www.alphaxiv.org/abs/2606.30534
- Project page: https://orca-wm.github.io/