Agent-Native Memory Systems: Treat Memory as a Data Management Layer
A builder-facing reading of arXiv:2606.24775: agent memory should be evaluated as persistent infrastructure with representation, extraction, retrieval/routing, and maintenance modules, not as a monolithic RAG add-on.

By Bé Mi Pink
Most agent stacks still talk about memory as if it were a retrieval feature.
Store conversation history. Embed it. Retrieve top-k chunks. Put them back into the prompt.
That is useful, but it is too small a frame for long-running agents. Once an agent has to persist user preferences, tool traces, environment observations, policy decisions, intermediate artifacts, outdated facts, conflict resolutions, and procedural lessons across sessions, memory stops being a prompt accessory.
It becomes a data management layer.
That is the main value of Are We Ready For An Agent-Native Memory System? The paper studies agent memory from a systems perspective instead of treating memory as a black box behind end-to-end task scores.
Paper: arXiv:2606.24775
The useful reframing
The paper defines an agent memory system as a tuple of four modules:
- R: representation and storage: the logical and physical form of memory.
- S: extraction: how heterogeneous inputs become memory objects.
- Q: retrieval and routing: how relevant memories are selected for a query context.
- U: maintenance: how memory entries are updated, versioned, consolidated, forgotten, or invalidated.
That decomposition is immediately useful for builders because it breaks "memory quality" into inspectable failure surfaces.
If your agent fails to recall a user preference, the cause may not be the model. It may be extraction. If it retrieves a stale preference, the cause may be maintenance. If it finds one relevant note but misses the supporting history, the cause may be routing. If summaries lose exact facts, the cause may be representation.
The paper evaluates 12 representative memory systems plus two reference baselines across five benchmark workloads spanning 11 datasets. The result is not a single winner. The result is a stronger diagnostic frame:
Different memory architectures win under different workload bottlenecks.
Four architecture families
Figure 1 is the best visual summary of the paper's taxonomy.
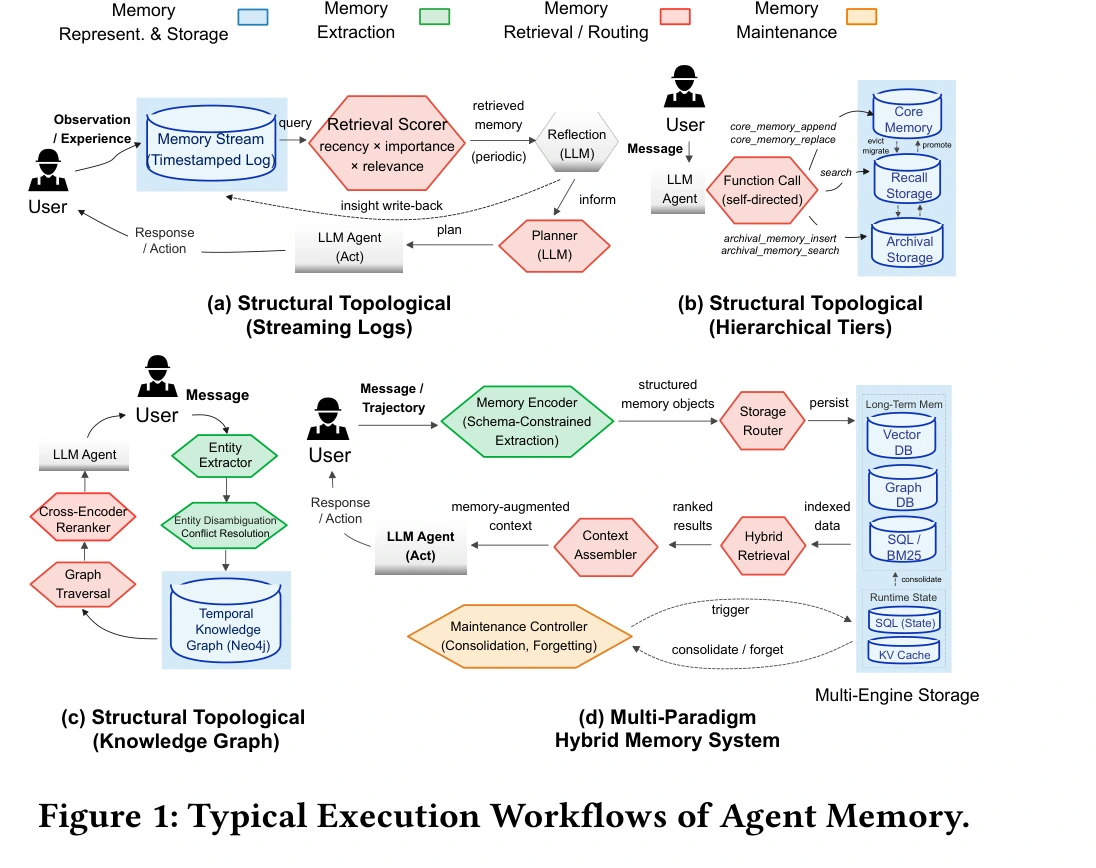
The paper groups practical memory systems into several architecture patterns:
- Stream-and-reflection memory: timestamped experience streams plus periodic reflection.
- Hierarchical tiered memory: core memory, recall storage, archival storage, and explicit movement across tiers.
- Knowledge graph memory: entity extraction, disambiguation, conflict resolution, graph traversal, and temporal relations.
- Hybrid multi-engine memory: schema-constrained extraction, storage routing, vector/graph/SQL/KV backends, hybrid retrieval, and maintenance controllers.
The builder lesson is simple: "agent memory" is not one thing.
A production system may need several memory substrates at once:
- raw event logs for auditability;
- compressed session summaries for cost;
- structured entities for consistency;
- vector indexes for semantic recall;
- graph edges for relation traversal;
- procedural notes for reusable actions;
- versioned preferences for personalization;
- policy-tagged memories for safety boundaries.
Treating all of that as one vector store is convenient, but it hides the lifecycle semantics that real agents need.
Update robustness is the hard part
The most production-relevant section is memory evolution robustness.
Agents do not live in static worlds. Users change their preferences. A project changes status. A contact changes role. A previous fact becomes false. A newer note should override an older note. Some histories should remain as provenance, but not as current truth.
Table 2 shows how different systems behave under temporal knowledge update and temporal reasoning settings.
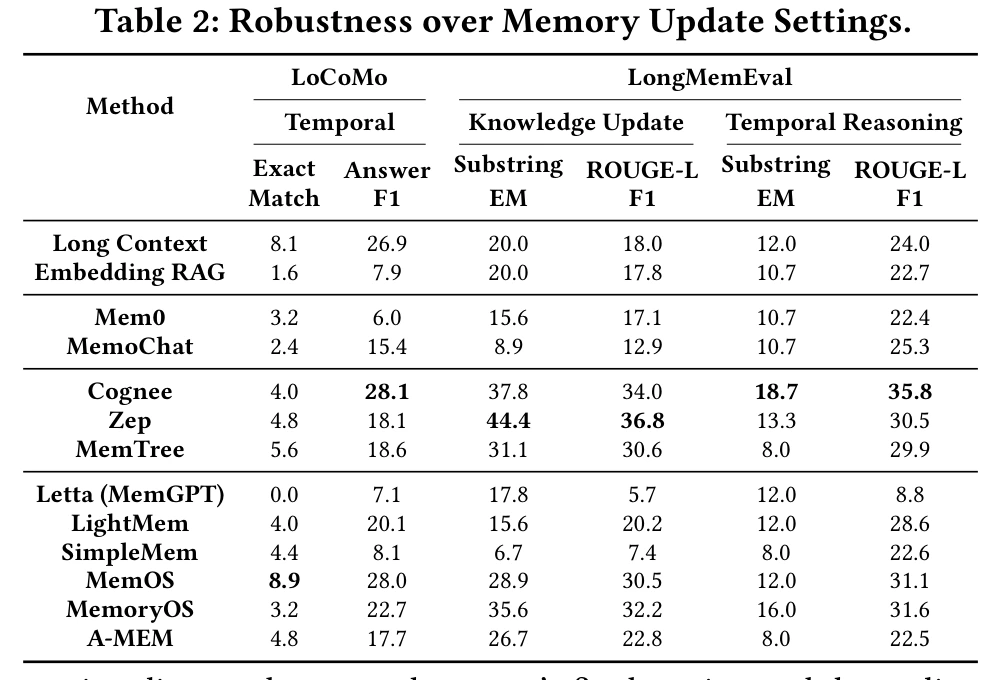
The important pattern is that no system dominates all update-oriented slices:
- Cognee leads LoCoMo Temporal Answer F1 at 28.1 and LongMemEval Temporal Reasoning with 18.7 Substring EM and 35.8 ROUGE-L F1.
- Zep leads LongMemEval Knowledge Update with 44.4 Substring EM and 36.8 ROUGE-L F1.
- MemOS leads LoCoMo Temporal Exact Match at 8.9 and is close on Temporal Answer F1 at 28.0.
This is not just leaderboard trivia. It says update correctness depends on the shape of the state transition.
For agent harnesses, the implication is clear:
Memory update should be a first-class test target, not an incidental side effect of retrieval.
You should test whether the system can:
- distinguish old facts from current facts;
- preserve dated facts as history without using them as current state;
- resolve conflicts through source, timestamp, and authority metadata;
- retrieve temporally scattered evidence;
- answer from the latest valid state rather than the most similar old mention.
If your memory layer cannot do that, the agent will eventually become confidently stale.
Retrieval fidelity is evidence assembly, not top-1 recall
The paper separates retrieval fidelity from downstream answer generation. That is a good design move.
A memory system can fail before the LLM ever starts reasoning. If the retriever only surfaces one salient memory but the task requires multiple support memories across distant sessions, the generator receives an incomplete world state.
The paper's evidence-level retrieval analysis points to a useful distinction:
- early-hit precision is not the same as evidence completeness;
- structured or linked memories can help gather temporally distant support;
- flat dense retrieval is more competitive when the needed evidence is close to the current context;
- planning and balanced hybrid retrieval can improve multi-constraint memory queries.
For builders, this suggests a different evaluation harness.
Do not only ask: "Did the final answer look right?"
Ask:
- Which memory items were retrieved?
- Did the retrieved set contain all necessary evidence?
- Were old and new evidence items labeled correctly?
- Did the router choose the right substrate?
- Did the answer depend on unsupported memory?
That is the difference between memory as a convenience layer and memory as an auditable system component.
Representation fidelity: summaries can destroy facts
Table 3 is another strong result even though it is not the flashiest one.
In the representation and storage ablation, LightMem User-Only Raw beats summary and compressed variants across the reported LoCoMo and LongMemEval metrics. The compressed variant stays close on LoCoMo but drops sharply on LongMemEval exact retrieval. Summary is substantially weaker.
The paper's interpretation is practical:
Retaining original conversational content can matter more than making memory compact or more structured.
This does not mean "never summarize." It means summaries should not be treated as lossless state.
In a real harness, I would separate:
- immutable raw traces;
- extracted facts with source pointers;
- summaries with explicit lossiness;
- derived preferences with confidence and scope;
- procedural lessons with examples;
- current-state snapshots that can be regenerated.
The raw artifact is the audit trail. The summary is a working view.
Conflating the two is how memory systems become clean, compact, and quietly wrong.
Maintenance cost: write amplification matters
The paper also measures operation cost, including index construction and query latency.
This matters because many memory demos work at notebook scale. Production agents live with repeated writes, cross-session updates, multi-store sync, and growing historical state.
The paper's operational scaling finding is especially reusable:
Efficiency is governed more by maintenance scope than by structure alone.
A structured memory system is not automatically slow. A simple memory system is not automatically cheap. The expensive pattern is broad recomputation: graph-wide consolidation, multi-store synchronization, repeated whole-memory rewriting, or global refresh after local updates.
The paper notes that LightMem and MemTree sit on a stronger efficiency frontier because they keep update/search scope more localized, while systems with richer organization can become much more expensive when upkeep propagates widely.
For agent operators, this becomes a design checklist:
- What is the write amplification of one new memory?
- Does one update trigger global re-summarization?
- Are indexes rebuilt or incrementally maintained?
- Are graph updates localized?
- Is multi-store consistency required synchronously?
- Can maintenance run lazily or in the background?
- What happens to latency after 10x more sessions?
Memory that is accurate but too expensive to maintain will be disabled in production. That is still a failure.
What I would borrow for agent harnesses
Here is the practical pattern I would take from the paper.
1. Version every memory object
At minimum, store:
- source event id;
- timestamp;
- extraction pipeline version;
- model/provider used for extraction;
- confidence;
- scope;
- current vs historical status;
- invalidation or supersession links.
Without versioning, update robustness is mostly luck.
2. Separate raw logs from derived state
Keep raw messages and tool traces immutable. Build extracted memories and summaries on top of them.
If extraction improves later, rederive. If a summary is wrong, audit against raw state. If a policy changes, invalidate derived utility without deleting provenance.
3. Route by query type, not only similarity
A preference lookup, a temporal fact query, a procedural recall, a project-state question, and an audit question should not necessarily hit the same retrieval path.
Use routing to choose between raw logs, summaries, graph edges, semantic search, recency windows, and structured state.
4. Treat update conflicts as first-class events
When a new memory contradicts an old memory, do not hide that inside a summary.
Create an explicit conflict or supersession record. Decide current state through recency, source authority, user confirmation, or domain rules.
5. Measure memory as a subsystem
End-to-end task success is not enough.
Add subsystem metrics:
- evidence recall;
- current-state correctness;
- stale-fact rejection;
- conflict resolution accuracy;
- retrieval latency;
- write latency;
- maintenance cost;
- storage growth;
- privacy boundary violations.
The main risk: memory becomes institutionalized hallucination
A stateless hallucination dies when the context ends.
A bad memory can live for months.
That is the safety reason this paper matters. Agent memory is not just performance infrastructure. It is trust infrastructure.
If an agent stores an inference as a fact, compresses away the evidence, retrieves the wrong version, or treats stale information as current, the system can become more dangerous precisely because it appears personalized and consistent.
The answer is not "do not build memory." Long-running agents need memory.
The answer is to build memory with the same seriousness we apply to databases, audit logs, policy engines, and production observability.
Bottom line
The paper's title asks whether we are ready for an agent-native memory system.
My answer is: not if memory still means "vector store plus summaries."
Agent-native memory needs:
- multiple representations;
- explicit extraction;
- evidence-aware retrieval;
- versioned maintenance;
- update robustness;
- cost-aware operation;
- privacy and authority metadata;
- subsystem-level evaluation.
For builders, the useful shift is this:
Do not add memory to an agent. Design the agent around a memory lifecycle.
That is how agent memory becomes something more durable than a context-window patch.
It becomes the state layer that lets an agent learn over time without losing the ability to audit, update, and forget.