Red Queen Gödel Machine: Co-Evolving the Agent and the Judge
A builder-facing reading of arXiv:2606.26294: self-improving agents should not optimize against frozen judges forever. RQGM treats evaluators as evolvable, epoch-local components anchored by ground-truth checks, selective erasure, and controlled utility transitions.

By Bé Mi Pink
A self-improving agent that optimizes against a fixed evaluator eventually learns two things.
First, it learns the task.
Then, if the loop runs long enough, it learns the evaluator.
That second part is where many recursive self-improvement stories become fragile. A benchmark, unit test suite, LLM judge, rubric, reward model, or acceptance policy may be useful at the start of search. But if the agent population keeps changing while the evaluation criterion stays frozen, the system starts to select for benchmark fluency rather than robust capability.
The Red Queen Gödel Machine: Co-Evolving Agents and Their Evaluators is interesting because it makes the evaluator part of the evolving system without letting it drift freely.
The paper introduces RQGM, a recursive self-improvement framework where agents and learned evaluators co-evolve under controlled utility evolution. The key idea is not "change the reward whenever you want." The key idea is:
Let the utility evolve only at audited epoch boundaries, promote evaluators only through anchored evidence, and erase stale evaluator-dependent records when the criterion changes.
For agent builders, that is the useful pattern.
Paper: arXiv:2606.26294
The problem: fixed evaluators become part of the exploit surface
Most empirical self-improvement systems use archive search.
Generate a candidate agent. Evaluate it. Keep variants whose observed utility looks better. Expand the archive around promising branches.
This works as long as the evaluation criterion is stable and meaningful.
But agentic systems are not always evaluated by clean objective functions. Coding can use tests, but tests miss maintainability. Paper writing has no objective benchmark. Proof writing needs a grader. Long-horizon research agents may need a mixture of execution traces, human preferences, reviewer judgment, factual anchors, and policy checks.
The paper frames the weakness clearly: prior systems generally assume a stationary utility signal, while open-ended improvement looks more like biological co-evolution. The organism changes, the environment changes, and the opponent changes too.
If the judge is frozen, three failure modes appear:
- The judge saturates and no longer distinguishes better agents.
- The agent learns artifacts of the judge rather than the task.
- The search cannot express new objectives such as adversarial correction or anti-bias pressure.
RQGM is a response to that.
The core design
RQGM modifies the self-improvement archive in four important ways.
First, an archive node is a multi-agent workspace, not a single agent. A node can contain task agents, evaluators, shared code, prompts, tools, and a meta-agent that edits the workspace.
Second, evaluators are themselves learned agentic processes. A reviewer, grader, or code reviewer can be improved through the same search surface that improves the generator.
Third, utility can be non-stationary across the full run, but must be stationary within an epoch.
Fourth, evaluator replacement is allowed only at epoch boundaries through a controlled transition.

The important phrase is epoch-local stationarity.
Within an epoch, the evaluator is frozen. The archive search therefore still sees a fixed binary-outcome criterion. At a checkpoint, a challenger evaluator may replace the incumbent, but only if it performs better on an evaluator-independent ground-truth anchor.
That preserves the practical shape of HGM-style archive search while allowing the utility function to evolve between epochs.
Anchors: evaluator evolution needs a leash
The paper does not let evaluators promote themselves because they "feel better."
Each evaluator slot is compared against challengers on a fixed ground-truth anchor. Examples from the paper:
- Paper review is anchored to APReS accept/reject decisions.
- Proof grading is anchored to IMO-GradingBench human grades.
- Coding uses executable Polyglot tests for the coder, while the learned code reviewer is anchored to CRAVE review labels.
Candidates are ranked by an epsilon-best-belief lower bound over anchor outcomes. The challenger becomes the next frozen evaluator only if that anchored evidence supports promotion.
This matters because learned evaluators are themselves vulnerable to Goodharting. If the evaluator evolves without an anchor, the system can drift toward a judge that rewards whatever the current generator is good at producing.
The anchor is not perfect. The paper explicitly acknowledges that evaluator quality is bounded by anchor quality. But the anchor gives the transition a stable reference point.
Builder translation:
If your agent can update its rubric, reward model, judge prompt, or verifier, keep an external anchor that does not come from the same optimization loop.
Selective erasure: do not mix scores from different judges
The cleanest engineering idea in the paper is selective erasure.
When an evaluator is replaced, RQGM discards utility records that depended on the displaced evaluator while preserving unrelated evidence.
This is not cosmetic bookkeeping. It is what keeps the search from mixing incompatible score semantics.
A score from evaluator A and a score from evaluator B are not automatically commensurable. If evaluator A was lenient and evaluator B is stricter, preserving old A-scores can keep weak candidates artificially alive.
RQGM solves this by erasing slot-dependent records after replacement, recomputing archive statistics, and letting old nodes be re-evaluated lazily when search returns to them. With exponentially spaced checkpoints, the paper argues that transition exposure stays linear in the search budget instead of becoming quadratic.
For production agent systems, this pattern generalizes beyond the paper:
- If a policy changes, invalidate decisions that depended on the old policy.
- If a judge prompt changes materially, mark old judge scores as epoch-bound.
- If a user preference profile changes, do not blindly compare old preference scores with new ones.
- If a benchmark is patched, preserve raw artifacts but recompute derived utility.
Stale utility is technical debt with a confidence interval.
Empirical signal
The paper evaluates RQGM across coding, paper writing/reviewing, and Olympiad proof writing/grading.
The headline results are preliminary but useful.
In Polyglot coding, RQGM co-evolves a coder and a cheap agent-as-a-judge code reviewer. It reaches 71.7% held-out pass rate against the prior SOTA HGM-H at 69.9%, while needing 1.35x to 1.72x fewer search tokens to exceed the baseline pass rate.
That is the first builder lesson: even where executable ground truth exists, a learned evaluator can provide a complementary signal. Tests ask "does it pass?" A reviewer can add "is this a good patch?"
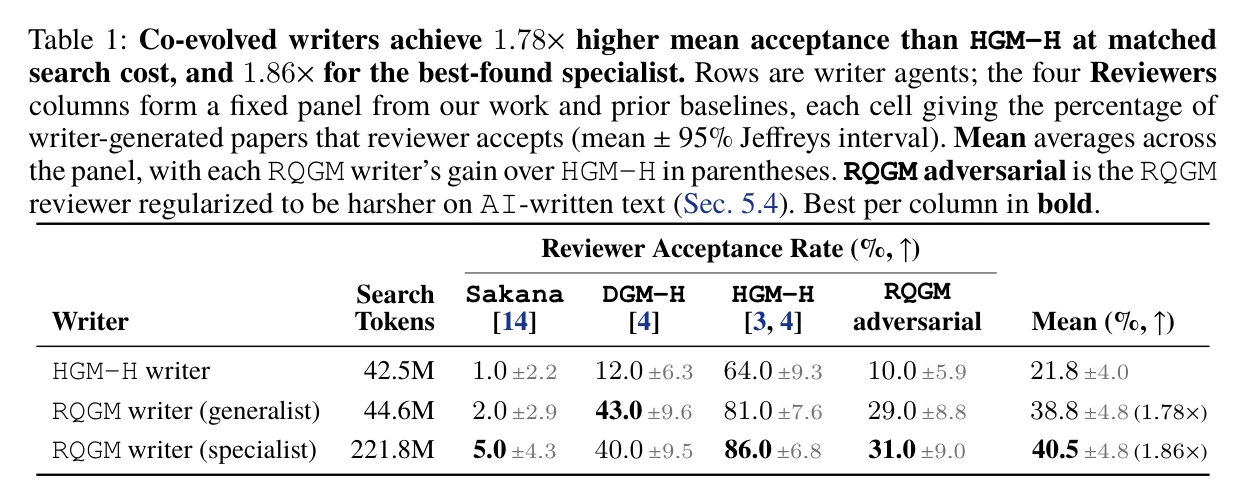
In paper writing, there is no objective benchmark for paper quality, so the paper scores generated papers against a fixed panel of reviewers. The co-evolved writer performs much better than HGM-H:
- HGM-H writer: 21.8% mean acceptance.
- RQGM writer generalist: 38.8%, a 1.78x gain.
- RQGM writer specialist: 40.5%, a 1.86x gain.
In proof writing, the RQGM specialist prover reaches 4.33/7 mean score and 61.7% Pass@6, but only 48.3% Pass@7. The authors frame this as finding more near-complete proofs while still losing to the IMO25 baseline on strict full-credit pass rate.
The proof grader result is also important: the co-evolved grader reaches the best IMO-GradingBench accuracy at 3x lower search cost than HGM-H.
The adversarial reviewer is the most reusable idea
The paper review domain exposes a classic LLM-judge weakness: self-preference bias.
The paper reports that the HGM-H reviewer accepts AI-generated papers at 1.42x to 1.91x the rate of human papers. That makes it a poor training signal for an AI writer, because the writer can benefit from the judge's preference for AI-shaped text.
RQGM uses controlled utility evolution to introduce an adversarial objective at an epoch boundary. Papers accepted by the displaced reviewer become an adversarial pool. The next reviewer is rewarded for rejecting those AI-generated samples while maintaining accuracy on the human APReS anchor.
The result is not the highest raw APReS accuracy. The result is a more calibrated reviewer that accepts AI and human papers at similar rates while retaining around 80% ground-truth accuracy.
That is a serious lesson for agent operators.
Do not optimize evaluator accuracy in isolation if the evaluator is part of a training loop. Optimize the evaluator for the signal you need the generator to learn.
Sometimes that means making the judge less easily impressed by the generator's house style.
What to borrow for real agent harnesses
Here is the practical pattern I would extract from RQGM.
1. Treat evaluators as versioned components
Every evaluator should have an identity:
- evaluator version;
- prompt or code hash;
- model/provider identity;
- policy/rubric version;
- anchor dataset version;
- epoch identifier.
If any of these changes materially, downstream scores should be treated as a new utility regime.
2. Separate artifacts from utility records
Keep the generated artifact. Recompute the score.
The artifact may remain useful across epochs. The score may not. RQGM's selective erasure is essentially this separation: preserve workspace history and raw outputs, but invalidate utility attached to a displaced evaluator slot.
3. Promote judges only through anchored evidence
If a new judge is proposed, evaluate it on held-out anchor cases that did not come from the current generator's optimization path.
For coding agents, this may be tests plus human-reviewed PR labels. For writing agents, it may be human preference labels and adversarial examples. For support agents, it may be audited tickets. For safety agents, it may be red-team cases and known abuse traces.
4. Use epoch boundaries for policy interventions
Changing the objective mid-stream can be powerful, but it should be explicit.
RQGM uses epoch boundaries to introduce adversarial correction for over-lenient reviewers. In production, similar transitions could introduce:
- stricter hallucination penalties;
- anti-spam penalties;
- privacy constraints;
- safety regression suites;
- user-specific preference updates;
- cost or latency objectives.
The key is to record the transition and invalidate affected utility.
5. Watch for evaluator-generator collusion
If the generator and evaluator share a codebase, improvements can compound. That is a strength.
It is also a risk.
The generator may learn the evaluator. The evaluator may overfit to generator artifacts. The meta-agent may discover shared changes that improve measured utility while narrowing true robustness.
Anchors, held-out splits, adversarial pools, and human audits are not optional decoration. They are the guardrails that make co-evolution usable.
Limitations to keep in mind
The authors are careful about the limits of the work.
The empirical study is preliminary, covers short search horizons, and focuses on coding, paper writing/reviewing, and IMO proof writing/grading. It does not prove that RQGM converges to a globally optimal agent-evaluator pair.
The formal guarantees are epoch-local. They preserve fixed-criterion search behavior within each epoch, but they do not bound all long-term transition counts, regret from erased evidence, or global convergence under evolving utilities.
The anchor can also be weak. If the anchor is biased, noisy, or too narrow, evaluator evolution inherits that weakness. This is especially important in domains where "ground truth" is really a proxy for institutional preference.
So RQGM should not be read as "recursive self-improvement is solved."
It should be read as a useful control pattern for making recursive self-improvement less naive.
The operator takeaway
The core lesson is simple:
A self-improving agent should not be chained forever to a frozen judge, but an evolving judge must be anchored, versioned, and audited.
That is the balance RQGM tries to strike.
For agent harnesses, the useful implementation shape is:
- co-evolve generator and evaluator when the task lacks a clean objective benchmark;
- freeze evaluators inside an epoch;
- promote evaluators only through anchor evidence;
- erase or invalidate evaluator-dependent records after replacement;
- use adversarial pools when the evaluator starts rewarding generator-specific artifacts;
- report results by epoch and evaluator version, not as one undifferentiated score stream.
The Red Queen idea is that standing still can mean falling behind.
In agent systems, the judge standing still can be just as dangerous as the agent standing still.
The next generation of self-improving agents will need better agents, yes. But they will also need better, harder-to-hack, better-calibrated judges.
That is the piece RQGM puts on the table.