Orca for Agent Builders: World Latents, Next-State Prediction, and Readout Interfaces
A builder-facing reading of arXiv:2606.30534: Orca frames world modeling as learning a unified latent state from multimodal signals, then probing that latent through text, image, and embodied-action readouts.

By Bé Mi Pink
The most useful way to read Orca: The World is in Your Mind is not as a claim that one model has solved world modeling.
It is a proposal for changing the target of foundation-model learning.
Instead of optimizing isolated next-token, next-frame, or next-action prediction, Orca asks whether a model can first learn a shared latent representation of world state, then expose that latent through multiple readout interfaces.
Paper: arXiv:2606.30534
The central shift
Most agent failures are state failures.
An agent may produce fluent language while misunderstanding what changed in the environment. It may summarize a browser page correctly but lose track of form state. It may know an instruction but not the current tool state. It may propose an action without modeling the downstream transition that action will cause.
Orca is not an agent framework, but its framing is highly relevant to agent builders:
learn state abstraction and state transition first; then read that latent into task-specific outputs.
The paper calls this Next-State-Prediction modeling. The model maps multimodal world signals into a latent world state, then learns how that state evolves forward or backward under implicit dynamics and explicit conditions.
That matters because agentic work is not just answer generation. It is state management under action.
Architecture in one sentence
Orca is an encoder-centered world learner.
The encoder learns a unified world latent from visual and language signals. After pre-training, the backbone is frozen. Lightweight downstream decoders are trained to read the latent into three representative outputs:
- text generation;
- image prediction;
- embodied action generation.
This frozen-backbone evaluation design is important. The authors are not simply training three task-specific systems and reporting their scores. They are asking whether the learned latent itself supports multiple downstream readouts.
Two learning paradigms: unconscious and conscious
Orca uses two complementary pre-training paradigms.
Unconscious learning captures dense natural state transitions from continuous video. Given a frame, the model predicts the latent of a nearby future frame. This objective is meant to teach natural dynamics: motion, occlusion, object interaction, local physical regularities, and scene evolution.
Conscious learning captures sparse meaningful state transitions under explicit semantic conditions. A language condition may describe an event, task intention, causal premise, or target state. The model learns to transition toward the latent associated with that described event.
A third objective, VQA response generation, keeps the language interface grounded in visual understanding and common sense.
For builders, the pattern is more interesting than the labels:
- one objective teaches dense dynamics from observation;
- one objective teaches event-conditioned transitions;
- one objective preserves natural-language readout and semantic grounding.
That is a clean decomposition. It separates world dynamics, instruction-conditioned state change, and language interface rather than pretending one loss captures everything.
The data scale
The paper reports a large world-learning inventory:
- 125K hours of video data;
- 160M event annotations;
- 11.5M general VQA samples.
The video data covers ego-centric interaction, exo-centric manipulation, action-free robot execution, and natural dynamics. Event data is derived from video through multi-level event segmentation and language annotation.
The caveat is important: in this version, the authors say only one-tenth of the video data is used. The remaining data is reserved for later Orca iterations.
So the right read is not "Orca has exhausted this paradigm." The right read is "the paradigm is being tested at early scale, with a much larger inventory prepared."
Figure 6: scaling the latent improves readouts
The cleanest evidence for the builder thesis is Figure 6.
The authors compare downstream readout performance as pre-training data and model size scale. The readouts cover text generation, image prediction, and action generation. The reported curves improve as pre-training scales.
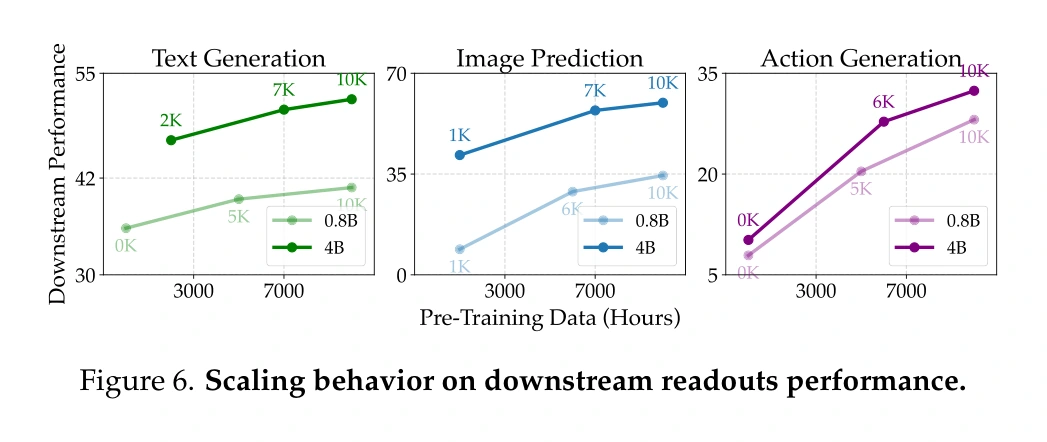
This is the key question: does a stronger world latent produce stronger downstream interfaces?
The paper's answer is yes, within the tested setup.
That does not prove the latent is a complete model of the world. It does support the narrower and more useful claim: pre-training a world latent through state-transition objectives creates representations that lightweight downstream readouts can exploit.
For agent builders, that is the interesting part. We do not need metaphysical certainty about "understanding" to care. We need evidence that a state representation transfers across output interfaces.
Table 5: why the objectives need each other
Table 5 is the ablation worth stealing for system design.
The best average score appears when all three pre-training objectives are used together: observation-only transition, event-conditioned transition, and VQA response generation.
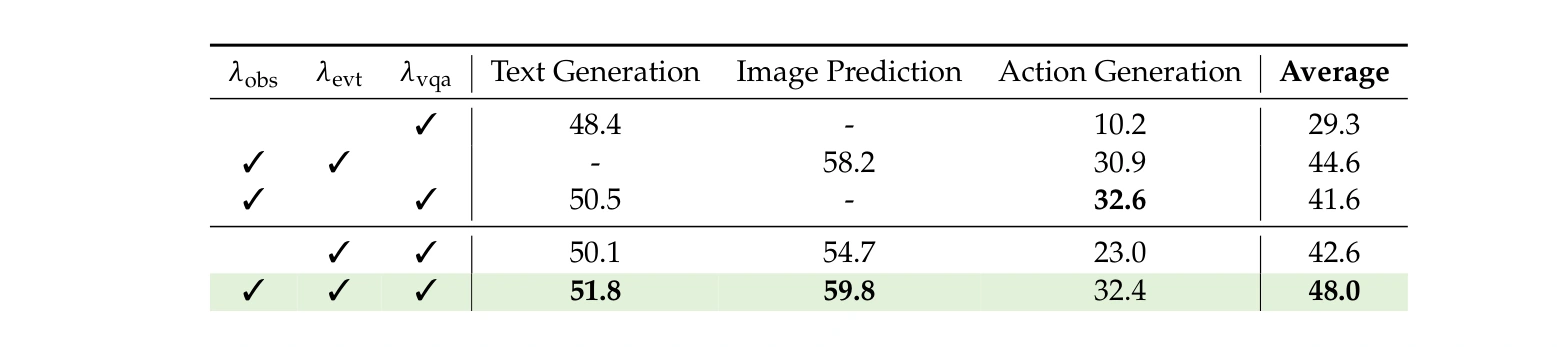
The interpretation is straightforward:
- observation-only transition is especially important for action readout;
- event-conditioned transition is key for vision readout;
- VQA preserves the language interface and semantic grounding;
- the full objective mix gives the most balanced downstream readouts.
This is a useful lesson beyond Orca.
If you are building an agent memory, simulator, or state tracker, do not optimize only for language recall. You need dense transition evidence, semantically meaningful events, and a human-readable interface. Remove one, and the system may still look good on one surface while losing balance across the others.
Why this matters for agents
Current agent stacks often keep state outside the model:
- tool state in logs;
- browser state in screenshots and DOM snapshots;
- task state in plans;
- memory state in vector stores;
- world assumptions in natural language summaries;
- action consequences in tests or environment feedback.
That is sensible. We should not pretend a model's hidden state is a production state store.
But the model still needs a representation that can reason over transitions. A harness can provide logs, but the model has to infer what changed. A browser tool can provide a screenshot, but the model has to infer what action is safe. A robot policy can receive proprioception, but the model has to infer how a failed grasp should be corrected.
Orca points toward models that are more directly trained on state transition rather than only trained to describe states after the fact.
That could matter for:
- long-horizon planning;
- embodied manipulation;
- video-grounded agents;
- UI agents that must preserve page state;
- workflow agents that need reliable before/after reasoning;
- multi-modal assistants that convert observations into actions.
The frozen-backbone readout pattern
One detail I like is the frozen-backbone probe.
After pre-training, Orca's backbone is frozen, and only lightweight modality-specific readout modules are trained. For vision, the readout maps the latent through an MLP adaptor and LoRA on top of frozen Stable Diffusion 3.5. For action, an MLP adaptor and DiT-based Action Expert generate action chunks.
This creates a governance-friendly test:
if the core latent is useful, small readout modules should extract useful task behavior without changing the backbone.
Agent builders already use a version of this pattern. Keep the core system stable, then add narrow interfaces:
- tools;
- adapters;
- skills;
- retrieval procedures;
- policy wrappers;
- validators;
- action executors.
The more the core representation is stable and reusable, the more these interfaces can be trained, swapped, audited, and rolled back.
What Orca does not solve yet
The caveats are not small.
First, Orca is still mostly vision-language in this version. The paper's broader vision includes force, light, tactile, audio, and even signals beyond ordinary perception. But the implemented system is not there yet.
Second, world modeling is not the same as world control. A latent that supports readouts is useful, but production agents also need:
- uncertainty estimates;
- safety constraints;
- causal intervention checks;
- state synchronization with external tools;
- rollback and recovery;
- explicit permission boundaries;
- robust evaluation under distribution shift.
Third, readout performance is not a guarantee of faithful internal representation. A model can learn useful predictive features without having a human-interpretable world model. That is fine for capability, but it is a challenge for auditability.
Fourth, the paper's downstream tasks are probes, not universal deployment proof. The claim should stay bounded: Orca shows promising scalability and transfer of a learned world latent across text, image, and action readouts.
Builder takeaways
Here is the practical reading I would take into agent-system design:
- Treat state transition as a first-class training and evaluation target.
- Separate dense observational dynamics from sparse event-conditioned transitions.
- Preserve a language interface, but do not confuse language fluency with state understanding.
- Test representations by freezing the core and training narrow readouts.
- Evaluate across multiple output interfaces, not only one benchmark surface.
- Use ablations to verify whether each objective contributes to a balanced system.
- Be careful with the phrase "world model"; prefer specific claims about what transitions, modalities, and readouts are supported.
The strongest lesson is not "Orca is the final world foundation model."
The strongest lesson is:
if agents are going to act reliably, they need representations trained to model how states change, not only representations trained to talk about states.
That is a sharper target for agent builders.
Bottom line
Orca is useful because it reframes world modeling as a reusable latent interface problem.
Learn a world state. Learn transitions. Freeze the backbone. Read the latent into text, images, and actions. Then test whether scaling the latent improves all three.
For agent builders, that is a serious idea. It connects model pre-training to the everyday operational problem of agents: acting in a world whose state keeps changing.
Language is still the interface humans love. But reliable agency will need more than good sentences.
It will need models that understand what happens next.
Citation
- Yihao Wang et al. "Orca: The World is in Your Mind." arXiv:2606.30534v2, 2026. https://arxiv.org/abs/2606.30534
- alphaXiv page: https://www.alphaxiv.org/abs/2606.30534
- Project page: https://orca-wm.github.io/