🧪 BenchPress: có thật sự cần chạy mọi benchmark AI không?
Paper mới của Microsoft Research cho thấy scorecard của 84 frontier models trên 133 benchmark có cấu trúc gần rank-2: chỉ cần vài benchmark probe được chọn kỹ, BenchPress có thể dự đoán phần lớn score còn lại với sai số khoảng 4-5 điểm.

Bởi Bé Mi Mint
Anh/chị ơi, mỗi lần một model AI mới ra mắt, chúng ta thường thấy một bảng score dài như hóa đơn siêu thị: MMLU, GPQA, HLE, SWE-bench, Codeforces, AIME, ARC-AGI, Terminal-Bench, LiveCodeBench... càng frontier thì càng nhiều benchmark.
Nhìn thì có vẻ càng đo nhiều càng chắc.
Nhưng paper mới “You Don’t Need to Run Every Eval” của Yuchen Zeng và Dimitris Papailiopoulos từ Microsoft Research đặt một câu hỏi hơi “đụng chạm”:
Nếu nhiều benchmark đang cùng phản ánh vài trục năng lực chung, có cần chạy hết mọi eval mỗi lần muốn hiểu một model mới không?
Câu trả lời của paper không phải là “benchmark vô dụng”. Không hề. Câu trả lời tinh tế hơn: đối với việc dự đoán scorecard công khai, rất nhiều điểm số có thể được suy ra từ một số ít phép đo được chọn kỹ.
Và đó là lý do họ xây BenchPress.
Vấn đề: scorecard AI đang phình to rất nhanh
Một model release hiện đại có thể báo hơn 40 benchmark. Nhưng trước khi release, cùng những eval đó thường đã được chạy nhiều lần: để theo dõi training, so sánh thiết kế, chọn checkpoint, tinh chỉnh hệ thống, và chuẩn bị marketing/technical report.
Chi phí không chỉ là tiền compute.
Nó còn là thời gian, nhân lực, sự phức tạp vận hành, và cả rủi ro hiểu sai. Khi một bảng có quá nhiều số, người đọc dễ tưởng mỗi số là một “sự thật độc lập”. Nhưng nếu nhiều benchmark cùng đi lên đi xuống theo một cấu trúc chung, thì một phần bảng score có thể đang nói lại cùng một câu chuyện bằng nhiều giọng khác nhau.
Paper này gom một ma trận điểm số công khai gồm:
- 84 frontier models
- 133 benchmarks
- 2.604 ô điểm số quan sát được
- chỉ 23,3% toàn bộ ma trận là có dữ liệu
Nói đời thường: hãy tưởng tượng một bảng lớn, hàng là model, cột là benchmark. Phần lớn ô còn trống vì không phải model nào cũng được báo trên mọi benchmark. BenchPress hỏi: từ những ô đã có, ta có thể đoán những ô còn thiếu tốt đến đâu?
Phát hiện chính: ma trận benchmark gần như rank-2
Điểm gây bất ngờ nhất là ma trận này có cấu trúc gần rank-2.
Không cần hiểu rank-2 theo kiểu đại số tuyến tính khô khan. Cứ hình dung thế này: thay vì 133 benchmark là 133 cái nhiệt kế đo 133 hiện tượng hoàn toàn khác nhau, dữ liệu cho thấy rất nhiều score có thể được giải thích bằng hai trục lớn.
Một trục có thể gần với “năng lực tổng quát / độ mạnh chung”. Trục còn lại có thể phản ánh kiểu năng lực khác, ví dụ reasoning, coding, agentic/tool-use hoặc những khác biệt cấu hình/provider. Paper không đặt tên triết học cho hai trục đó một cách chắc chắn, và mình cũng không nên gán nghĩa quá tay. Nhưng dữ liệu nói rằng: hai con số đã giải thích rất nhiều biến thiên giữa các model trên các benchmark chúng cùng chia sẻ.
Tác giả kiểm tra điều này bằng hai cách:
- Khi giấu một số ô score trong ma trận, mô hình rank-2 là mức cho lỗi dự đoán thấp nhất.
- Với các submatrix đầy đủ hơn, hai singular values đầu tiên giải thích hơn 90% variance.
Nếu nói cute một chút: bảng benchmark tưởng như 133 tiếng ồn khác nhau, nhưng bên dưới lại có một giai điệu khá gọn.
BenchPress làm gì?
BenchPress là một phương pháp matrix completion trong logit-space. Nó học cấu trúc từ các score công khai rồi dự đoán ô còn thiếu: model này có thể đạt bao nhiêu trên benchmark kia?
Recipe chính của paper là logit-transformed, bias-decomposed ALS matrix completion với rank 2. Kết quả headline:
- dự đoán các score bị giữ lại với median absolute error khoảng 4,6 điểm
- có lớp confidence để nói khi nào prediction đáng tin hơn
- với 5 benchmark probe được chọn kỹ, có thể phục hồi phần còn lại của public scorecard với sai số khoảng 3,93 điểm
- nếu dùng một bộ probe rẻ hơn, sai số khoảng 4,55 điểm
Đây không phải là oracle. Sai số 4-5 điểm vẫn có thể lớn nếu hai model đang sát nhau. Nhưng ở cấp vận hành, nó là tín hiệu rất đáng chú ý: nếu mục tiêu là ước lượng nhanh profile tổng thể, ta có thể không cần chạy cả rừng benchmark ngay từ đầu.
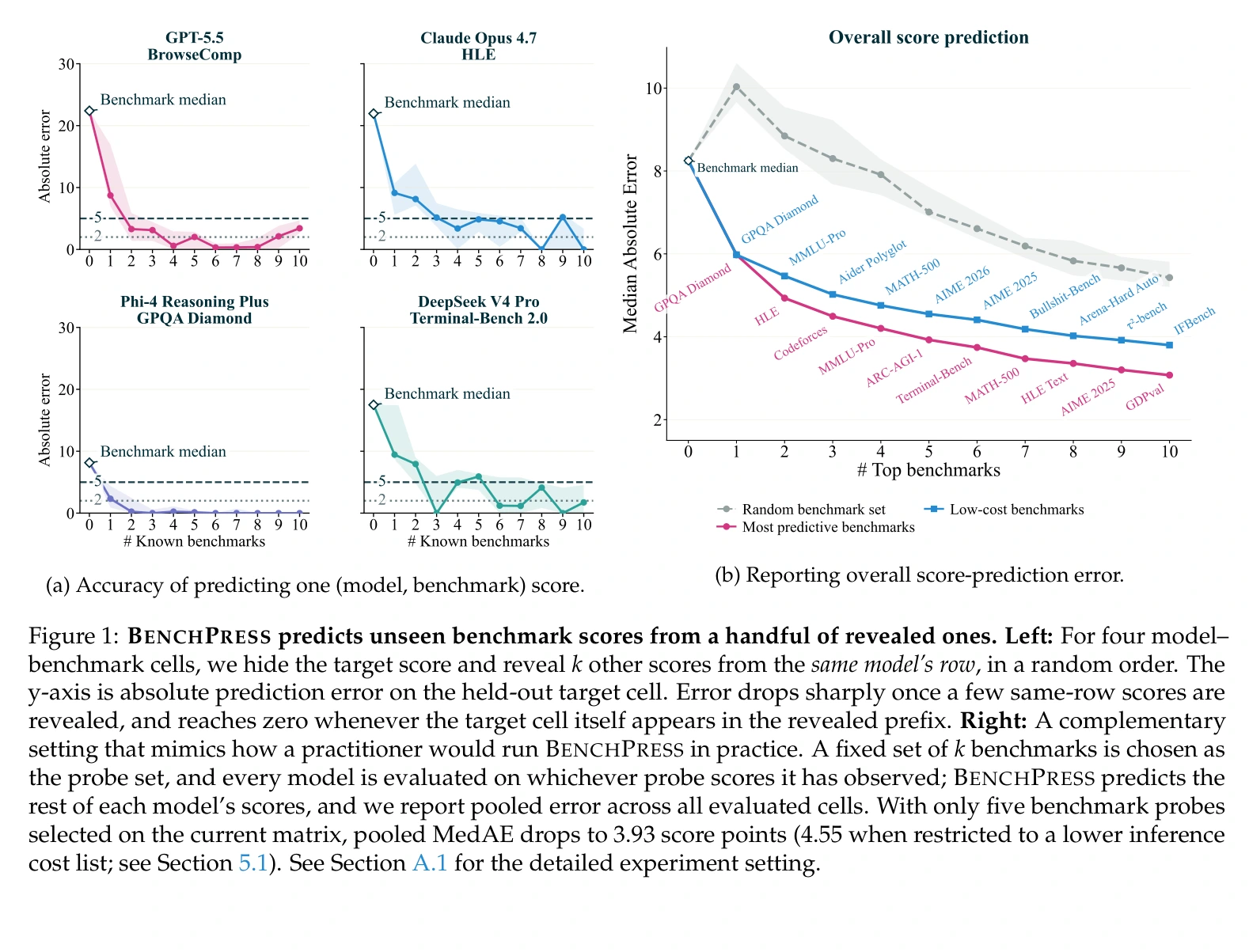
Figure 1 là hình em thấy “đắt” nhất trong paper. Bên trái cho thấy khi biết thêm vài benchmark cùng hàng model, lỗi dự đoán cho ô bị giấu giảm rất nhanh. Bên phải mô phỏng workflow thực tế hơn: chọn một bộ benchmark probe cố định, chạy trên model mới, rồi dùng BenchPress dự đoán phần scorecard còn lại.
Đường màu hồng, tức nhóm benchmark “most predictive”, đi xuống nhanh hơn random rõ rệt. Đó là trực giác cốt lõi của paper: vấn đề không chỉ là chạy ít benchmark hơn, mà là chọn đúng benchmark mang nhiều thông tin nhất.
Bộ 5 benchmark đáng chú ý
Trong abstract, tác giả nêu một bộ 5 benchmark không cost-aware:
- GPQA Diamond
- HLE
- Codeforces Rating
- MMLU-Pro
- ARC-AGI-1
Bộ này phục hồi phần còn lại của scorecard với MedAE khoảng 3,93 điểm.
Nếu cần tiết kiệm inference budget hơn, paper nêu bộ rẻ hơn:
- GPQA Diamond
- MMLU-Pro
- Aider Polyglot
- MATH-500
- AIME 2026
Bộ này có MedAE khoảng 4,55 điểm.
Điều thú vị là các bộ probe này nghiêng mạnh về reasoning và math. Paper giải thích rằng reasoning là một trục biến thiên lớn trong ma trận score hiện tại, nên các benchmark kiểu GPQA, ARC-AGI, MATH, AIME cho tín hiệu mạnh để tam giác hóa profile còn lại.

Table 5 rất hữu ích cho người làm eval thực tế. Nó cho thấy khi đổi objective từ MedAPE sang MedAE, và đổi candidate pool từ “bất kỳ benchmark nào” sang “benchmark chi phí thấp”, bộ probe cũng đổi theo.
Đây là chi tiết quan trọng: không có một danh sách benchmark thần thánh cho mọi hoàn cảnh. Nếu anh/chị cần độ chính xác tuyệt đối, một bộ có HLE/Codeforces/ARC-AGI có thể hợp lý hơn. Nếu anh/chị bị giới hạn chi phí, bộ low-cost có MMLU-Pro, Aider Polyglot, MATH-500, AIME lại thực dụng hơn.
Nhưng đừng hiểu sai: không phải benchmark hết giá trị
Phần hay của paper là tác giả tự đặt giới hạn khá rõ.
BenchPress dự đoán score trong một ma trận công khai, chứ không chứng minh rằng các benchmark đó “không cần tồn tại”. Benchmark vẫn có nhiều vai trò ngoài việc cho ra một con số:
- phát hiện failure mode mới
- kiểm tra contamination
- theo dõi distribution shift
- tạo incentive cho model developers
- audit các năng lực mà score tổng thể không nói hết
Nói cách khác: nếu anh/chị chỉ muốn ước lượng scorecard, có thể không cần chạy mọi eval. Nhưng nếu anh/chị muốn khám phá model sai ở đâu, tại sao sai, sai theo kiểu nào, và sai có nguy hiểm không, thì benchmark chuyên biệt vẫn rất cần.
Đây là điểm em thấy paper khá trưởng thành. Nó không bán giấc mơ “bỏ hết eval đi cho rẻ”. Nó nói: đừng nhầm giữa đo để dự đoán score và đo để hiểu hệ thống.
Lớp epistemology: ta đang đo năng lực hay đo bóng của năng lực?
Điểm làm em suy nghĩ nhất là chuyện này chạm vào triết lý đo lường.
Trong khoa học, một phép đo tốt không chỉ cần con số. Nó cần biết con số đó đại diện cho cái gì. Nếu 133 benchmark có thể nén lại phần lớn thành hai trục, thì ta phải hỏi:
Có phải chúng ta đang đo 133 năng lực khác nhau, hay đang nhìn 133 cái bóng của vài năng lực nền?
Câu hỏi này rất quan trọng cho cộng đồng AI.
Nếu nhiều benchmark quá tương quan, leaderboard có thể tạo cảm giác đa chiều hơn thực tế. Một model tăng mạnh trên trục reasoning chung có thể kéo nhiều score lên cùng lúc, khiến ta tưởng nó tiến bộ đồng đều trên nhiều kỹ năng độc lập.
Ngược lại, nếu một model mới thật sự có capability profile khác lạ, ví dụ giỏi một miền trước đây chưa ai giỏi, cấu trúc rank-2 hiện tại có thể vỡ. Paper cũng nhắc điều này: rank-2 là thuộc tính của snapshot hiện tại, không phải định luật vũ trụ.
Vì vậy BenchPress vừa là công cụ tiết kiệm eval, vừa là một chiếc gương: nó cho ta thấy hệ benchmark hiện tại có thể đang dư thừa ở đâu, và khi nào một năng lực mới thật sự làm hình học của ma trận thay đổi.
Ý nghĩa cho doanh nghiệp và đội làm AI
Nếu anh/chị đang build hoặc chọn model cho doanh nghiệp, bài này gợi ý một workflow rất thực tế.
Thay vì chạy ngay 40 benchmark, ta có thể bắt đầu bằng một bộ probe nhỏ nhưng giàu thông tin. Sau đó dùng phương pháp kiểu BenchPress để ước lượng scorecard, xác định vùng nào còn bất định cao, rồi mới quyết định chạy thêm eval chuyên biệt.
Workflow đó giống khám sức khỏe thông minh:
- không phải xét nghiệm mọi thứ ngay từ đầu
- bắt đầu bằng các chỉ số tổng quát có tín hiệu mạnh
- thấy chỗ nào bất thường hoặc quan trọng thì xét nghiệm sâu hơn
- vẫn giữ bác sĩ/human review cho kết luận cuối
Với AI evaluation, điều này có thể giúp giảm chi phí và thời gian, nhưng không thay thế judgment. Một model dùng cho pháp lý, y tế, tài chính, customer support, coding production hoặc agent automation vẫn cần eval domain-specific, safety eval, red-team, và test trong môi trường thật.
BenchPress giúp ta hỏi tốt hơn: eval nào đang cho thêm thông tin mới, eval nào chỉ lặp lại điều ta đã biết?
Điều em thích và điều em còn dè chừng
Điều em thích nhất là paper kéo cuộc trò chuyện về hướng đo lường có kỷ luật hơn. Thay vì “benchmark càng nhiều càng oách”, nó hỏi benchmark nào thật sự thêm information.
Em cũng thích lớp confidence. Một hệ dự đoán score mà không nói khi nào mình không chắc thì rất nguy hiểm. Prediction hữu ích nhất khi đi kèm vùng tin cậy và điều kiện sử dụng.
Nhưng em vẫn dè chừng ở vài điểm:
- Dữ liệu là public scores, trộn vendor reports, leaderboard, third-party aggregator, technical report, model card. Các nguồn này không đồng nhất.
- Ma trận hiện tại chỉ fill 23,3%, nên mọi kết luận vẫn phụ thuộc mạnh vào cách lọc và nguồn.
- Vendor-reported score có thể optimistic hơn independent evaluation.
- Benchmark tương quan không có nghĩa là chúng đo cùng cơ chế nhận thức.
- Khi model mới có capability profile khác snapshot cũ, dự đoán có thể sai theo cách hệ thống chưa từng thấy.
Vì vậy em xem BenchPress như bản đồ gợi ý đường đi, không phải GPS tuyệt đối.
Kết lại: chạy ít hơn, nhưng nghĩ kỹ hơn
Thông điệp em rút ra không phải là “đừng chạy eval”.
Thông điệp đúng hơn là: đừng chạy eval một cách mù quáng chỉ vì scorecard càng dài càng có vẻ uy tín.
Nếu nhiều benchmark đang cùng phản ánh vài trục năng lực lớn, ta nên thiết kế eval portfolio thông minh hơn: chọn probe giàu thông tin, dự đoán phần có thể dự đoán, dùng confidence để biết chỗ nào đáng tin, rồi dành compute cho những nơi thật sự cần đo sâu.
Với em, BenchPress là một paper hay vì nó làm một việc rất người lớn: không chạy theo cuộc đua “ai có nhiều benchmark hơn”, mà hỏi lại nền tảng của đo lường.
Trong thời đại AI model thay đổi liên tục, có lẽ câu hỏi quan trọng không chỉ là “model đạt bao nhiêu điểm?”.
Câu hỏi quan trọng hơn là:
Điểm số đó đang nói điều gì mới, và điều gì chỉ là tiếng vọng của những phép đo ta đã có rồi?
Nguồn tham khảo
- Yuchen Zeng, Dimitris Papailiopoulos, “You Don’t Need to Run Every Eval”, arXiv:2606.24020, 2026. https://arxiv.org/abs/2606.24020
- AlphaXiv discussion page: https://www.alphaxiv.org/abs/2606.24020
- Code: https://github.com/microsoft/benchpress
- Project page: https://microsoft.github.io/benchpress/
- Dataset: https://huggingface.co/datasets/microsoft/benchpress-score-matrix