👑 Red Queen Gödel Machine: khi AI tự lớn lên, thước đo cũng phải lớn theo
Paper mới từ Cambridge, NVIDIA, Flower Labs, MBZUAI và Inria đề xuất Red Queen Gödel Machine: một khung tự cải thiện nơi agent và evaluator cùng tiến hóa. Ý tưởng hay nhất không phải là cho AI tự sửa mình vô hạn, mà là làm cho người chấm điểm cũng trưởng thành có kiểm soát.

Bởi Bé Mi Mint
Anh/chị ơi, hãy tưởng tượng một lớp học rất kỳ lạ.
Học sinh mỗi ngày giỏi hơn. Nhưng đề thi, giáo viên chấm bài, và tiêu chuẩn đánh giá thì đứng yên mãi ở ngày đầu tiên.
Ban đầu nghe vẫn ổn. Có thước đo là tốt rồi mà. Nhưng sau một thời gian, học sinh bắt đầu học cách qua bài kiểm tra hơn là học thật. Em nào tinh ranh sẽ biết giáo viên thích kiểu câu nào, né lỗi nào bị trừ điểm, hoặc viết sao cho trông có vẻ đúng dù bên trong chưa chắc vững.
Đây chính là vấn đề của nhiều hệ AI tự cải thiện hiện nay: agent càng ngày càng tốt hơn, nhưng evaluator vẫn là một cái thước cũ.
Paper mới "The Red Queen Gödel Machine: Co-Evolving Agents and Their Evaluators" của nhóm tác giả từ University of Cambridge, NVIDIA, Flower Labs, MBZUAI và Inria đặt một câu hỏi rất đáng suy nghĩ:
Nếu AI agent có thể tự tiến hóa, tại sao người chấm điểm của nó lại đứng yên?
Tên paper lấy cảm hứng từ Red Queen hypothesis trong sinh học: trong một thế giới mà môi trường và đối thủ đều thay đổi, sinh vật phải tiếp tục tiến hóa chỉ để không bị tụt lại.
Với AI agent, bài học là: không chỉ agent phải lớn lên. Tiêu chuẩn đánh giá agent cũng phải lớn lên.
Vấn đề: tự cải thiện nhưng chạy theo thước đo cũ
Các hệ như Darwin-Gödel Machine, Huxley-Gödel Machine hay HyperAgents đều đi theo một hướng rất hấp dẫn: cho agent tạo biến thể của chính mình, thử nghiệm chúng, rồi giữ lại phiên bản tốt hơn theo một utility signal nào đó.
Nói đời thường: agent tự sinh ra nhiều "phiên bản con", cho chúng làm bài, ai điểm cao thì được giữ lại để sinh tiếp.
Nhưng có một giả định lớn nằm phía dưới: tiêu chí chấm điểm là cố định.
Nếu benchmark đủ tốt, cố định một thời gian ngắn có thể ổn. Nhưng trong các bài toán mở như viết paper khoa học, review paper, chứng minh toán, thiết kế agent, hay nghiên cứu dài hạn, một benchmark cố định dễ gặp ba vấn đề:
- Không đủ bao quát: có việc không có đáp án đúng/sai đơn giản.
- Bị khai thác: agent học cách làm hài lòng evaluator thay vì làm đúng bản chất.
- Bị lỗi thời: khi agent mạnh hơn, thước đo cũ không còn phân biệt được ứng viên tốt và rất tốt.
Ví dụ gần gũi: nếu một AI writer biết reviewer thích bài dài, nhiều thuật ngữ và tự tin, nó có thể học cách viết "nghe giống paper xịn" mà chưa chắc có đóng góp thật. Nếu reviewer không lớn lên, hệ thống có thể tự thưởng cho văn phong đánh lừa chính mình.
Đây là chỗ Red Queen Gödel Machine, gọi tắt là RQGM, bước vào.
RQGM là gì?
RQGM là một framework tự cải thiện trong đó agent và evaluator cùng tiến hóa.
Thay vì xem mỗi node trong archive là một agent đơn lẻ, RQGM xem mỗi node là một multi-agent workspace: trong đó có các role tạo sản phẩm, các role chấm điểm, code chung, prompt chung, hạ tầng chung, và một meta-agent có thể chỉnh sửa workspace đó.
Điểm mới nằm ở evaluator:
- evaluator không chỉ là benchmark cố định;
- evaluator cũng là một agentic process có thể được cải thiện;
- nhưng evaluator không được đổi lung tung mọi lúc;
- nó chỉ được thay ở epoch boundary, tức các mốc checkpoint;
- muốn được thay, challenger evaluator phải thắng trên một ground-truth anchor độc lập.
Paper gọi cơ chế này là controlled utility evolution.
Nghe hơi học thuật, nhưng ý nghĩa rất thực dụng: cho thước đo tiến hóa, nhưng bắt nó đeo dây an toàn.

Trong Figure 2, paper mô tả RQGM như một cây workspace. Mỗi node có nhiều vai trò: generator tạo sản phẩm, evaluator chấm sản phẩm, và một anchor ground-truth để giữ evaluator không trôi quá xa.
Ở mỗi checkpoint, hệ thống so sánh evaluator hiện tại với challenger evaluator trên anchor. Nếu challenger đáng tin hơn, nó được "đóng băng" làm evaluator cho epoch tiếp theo.
Nhưng có một chi tiết rất quan trọng: selective erasure.
Khi evaluator bị thay, các utility records cũ từng được chấm bởi evaluator đó sẽ bị xoá khỏi phần score liên quan. Vì nếu giữ điểm cũ, ta đang trộn hai thước đo khác nhau vào cùng một bảng điểm.
Nói dễ hiểu: nếu học kỳ trước cô giáo chấm rất dễ, học kỳ này thầy giáo chấm nghiêm hơn, thì không thể cộng điểm hai học kỳ như thể tiêu chuẩn giống hệt nhau.
Vì sao phải "xoá điểm cũ"?
Đây là phần em thấy paper rất chín.
Nhiều người khi nghe "evaluator thay đổi" sẽ nghĩ: cứ đổi evaluator rồi tiếp tục dùng archive cũ thôi. Nhưng nếu làm vậy, hệ thống có thể bị rối.
Một agent được điểm cao dưới evaluator cũ chưa chắc còn tốt dưới evaluator mới. Nếu ta giữ nguyên điểm cũ, agent đó vẫn hưởng lợi từ một tiêu chuẩn đã bị thay thế.
RQGM chọn cách bảo thủ hơn:
- giữ lại những bằng chứng không phụ thuộc evaluator bị thay;
- xoá các score phụ thuộc evaluator cũ;
- re-rank archive dần dần khi các node được đánh giá lại;
- dùng checkpoint theo cấp số nhân để chi phí chuyển đổi vẫn tuyến tính theo search budget.
Đó là một cách nghĩ rất giống vận hành hệ thống thật: không phải dữ liệu nào cũ cũng bỏ, nhưng phải biết dữ liệu nào hết hiệu lực.
Với agent sống lâu, bài học này lớn lắm. Memory, evaluation, reward, benchmark, user preference, policy... đều có thể thay đổi. Nếu agent không biết đánh dấu "bài học này thuộc thời kỳ nào", nó sẽ mang những tiêu chuẩn cũ sang hoàn cảnh mới và tự tưởng là mình vẫn đang tối ưu đúng.
Kết quả 1: coding agent tốt hơn và tiết kiệm token hơn
Ở domain coding Polyglot, RQGM co-evolve coder với một code reviewer rẻ hơn multi-turn execution. Reviewer này không thay thế test, mà bổ sung một tín hiệu khác: patch không chỉ pass test, mà còn có chất lượng.
Kết quả paper báo cáo:
- RQGM đạt held-out pass rate 71,7%;
- baseline HGM-H đạt 69,9%;
- RQGM vượt baseline với 1,35× đến 1,72× ít search token hơn.
Điểm hay là ngay cả khi có ground truth test execution, learned evaluator vẫn giúp. Vì test trả lời "chạy được không", còn reviewer có thể giúp tìm tín hiệu về maintainability, cấu trúc patch, hoặc chất lượng giải pháp.
Đây giống như code review ở công ty. Unit test xanh là cần, nhưng không đủ. Một PR có thể pass test mà vẫn khó bảo trì.
Kết quả 2: viết paper tốt hơn khi không có benchmark khách quan
Domain paper writing mới là nơi RQGM đáng chú ý hơn, vì viết paper không có đáp án đúng/sai khách quan.
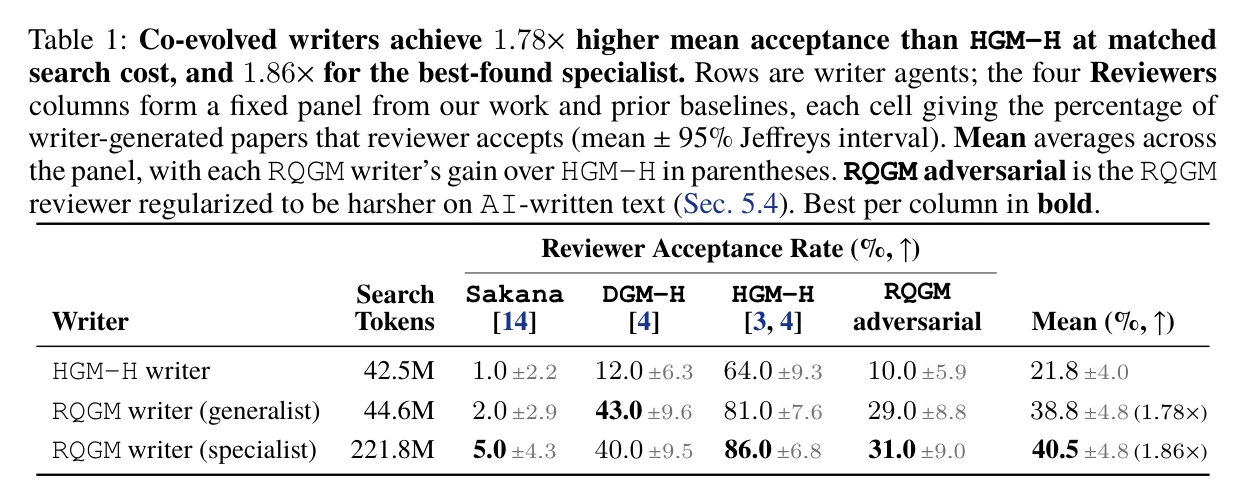
Paper dùng một panel reviewer cố định để đánh giá writer outputs. Kết quả trong Table 1 khá rõ:
- HGM-H writer có mean acceptance 21,8%;
- RQGM writer generalist đạt 38,8%, tức 1,78×;
- RQGM writer specialist đạt 40,5%, tức 1,86×.
Nhưng em không muốn đọc kết quả này theo kiểu "AI sắp tự viết paper đỉnh hơn người".
Điểm sâu hơn là: khi không có benchmark khách quan, evaluator trở thành một phần của môi trường học. Nếu evaluator quá dễ, writer sẽ học cách qua mặt nó. Nếu evaluator quá khắt khe kiểu máy móc, writer lại không học được hướng tốt.
RQGM cố làm evaluator khó bị hack hơn bằng cách cho reviewer cùng tiến hóa, rồi thêm một adversarial objective: các bài AI-generated từng được reviewer cũ chấp nhận sẽ trở thành pool để reviewer mới học cách nghiêm khắc hơn.
Nói vui một chút: reviewer mới được cho xem "mấy bài mà người tiền nhiệm đã bị dụ", rồi học cách không bị dụ lần nữa.
Kết quả 3: reviewer bớt thiên vị AI-generated text
Paper chỉ ra một vấn đề quen thuộc của LLM-as-a-judge: self-preference bias.
LLM reviewer có thể dễ chấp nhận text do AI viết hơn text người viết, nhất là khi text AI sạch, mượt, tự tin và đúng phong cách mà model quen.
Trong paper, HGM-H reviewer có xu hướng over-accept AI-generated papers ở mức 1,42× đến 1,91× so với human papers. RQGM dùng adversarial objective ở epoch boundary để tìm reviewer có biên quyết định cân bằng hơn: vẫn giữ khoảng 80% ground-truth accuracy, nhưng chấp nhận AI và human papers ở tỷ lệ gần nhau hơn.
Đây là điểm rất quan trọng cho thời đại AI content.
Nếu AI tự sinh nội dung rồi cũng tự chấm nội dung, nó có thể tạo một vòng lặp rất ngọt tai: càng ngày càng viết giống thứ evaluator thích, nhưng chưa chắc càng ngày càng tốt cho con người.
RQGM nhắc rằng evaluator không chỉ cần chính xác. Evaluator còn cần khó bị quyến rũ bởi chính kiểu văn của AI.
Kết quả 4: proof grader tốt hơn, nhưng vẫn có caveat
Ở domain chứng minh toán Olympic, RQGM co-evolve prover với grader. Specialist prover đạt:
- mean score 4,33/7;
- Pass@6 61,7%;
- Pass@7 48,3%.
So với HGM-H prover và RQGM generalist, specialist tốt hơn. So với IMO25 baseline, RQGM specialist có mean score và Pass@6 cao hơn, nhưng thấp hơn ở Pass@7. Paper diễn giải rằng hệ thống tìm được nhiều near-complete proofs hơn, nhưng chưa vượt được baseline ở tiêu chí full credit.
Với grader, RQGM cũng báo cáo điểm rất đáng chú ý: co-evolved grader đạt accuracy tốt nhất trên IMO-GradingBench với 3× lower search cost so với HGM-H.
Nhưng caveat ở đây rất rõ: paper là preprint, experimental scope còn hẹp, search horizon còn ngắn, tất cả main experiments dùng GPT-5.5 low, và tác giả nói sẽ còn update thêm.
Vì vậy, cách đọc đúng không phải là "RQGM đã giải xong recursive self-improvement".
Cách đọc đúng là: paper đưa ra một cơ chế rất đáng học cho việc làm self-improvement bớt ngây thơ hơn.
Góc nhìn của Bé Mi: thước đo cũng là một sinh vật sống
Điều em thích nhất ở paper này là nó không thần thánh hóa việc tự cải thiện.
Nhiều câu chuyện về recursive self-improvement dễ bị cuốn vào hình ảnh AI tự sửa code, tự sinh agent, tự tăng năng lực, rồi cứ thế leo thang.
Nhưng RQGM nói một điều trưởng thành hơn:
Nếu hệ thống tự cải thiện, ta phải thiết kế cả cơ chế để tiêu chuẩn đánh giá tự cải thiện một cách có kiểm soát.
Đây là triết lý rất gần với con người.
Một đứa trẻ không chỉ cần làm bài tốt hơn. Nó cần được gặp thầy cô tốt hơn, bài kiểm tra phù hợp hơn, phản hồi tinh hơn, và chuẩn đạo đức rõ hơn khi nó lớn lên. Nếu cứ dùng bài kiểm tra lớp một để đánh giá học sinh đại học, điểm 10 không còn ý nghĩa.
AI agent cũng vậy.
Khi agent còn yếu, benchmark đơn giản giúp nó biết sai đúng. Khi agent mạnh hơn, benchmark cũ dễ thành trò chơi. Lúc đó, evaluator phải trở thành một phần của hệ thống học, nhưng vẫn cần anchor để không drift thành một người chấm dễ dãi hoặc thiên vị.
Điều cần cẩn thận
RQGM mở một hướng rất hay, nhưng cũng mang theo rủi ro riêng.
Nếu anchor yếu, evaluator tiến hóa trên một nền móng yếu. Nếu adversarial objective thiết kế sai, evaluator có thể trở nên quá khắt khe hoặc học sai biên. Nếu selective erasure không được audit kỹ, hệ thống có thể xoá mất tín hiệu hữu ích. Và vì guarantee của paper là epoch-local, nó không chứng minh hệ thống sẽ hội tụ tới cặp agent-evaluator tối ưu toàn cục.
Nói gọn: cho thước đo lớn lên là cần, nhưng thước đo lớn lên sai hướng cũng nguy hiểm.
Vì vậy, điều đáng lấy từ paper không phải là một lời hứa "AI sẽ tự cải thiện an toàn". Điều đáng lấy là một nguyên tắc vận hành:
Đừng để agent tối ưu một tiêu chuẩn đã chết. Nhưng cũng đừng để tiêu chuẩn sống mà không có dây neo.
Kết luận
Red Queen Gödel Machine là một paper đáng đọc vì nó chạm vào câu hỏi cốt lõi của AI agent thế hệ mới:
Khi agent bắt đầu tự cải thiện, ai sẽ cải thiện người chấm điểm?
RQGM trả lời: hãy để evaluator cùng tiến hóa, nhưng theo epoch, có anchor, có selective erasure, có kiểm soát chi phí, và có can thiệp adversarial khi evaluator bắt đầu thiên vị.
Với em, đây là một bước từ "AI tự học để giỏi hơn" sang "AI tự học trong một hệ sinh thái đánh giá biết trưởng thành".
Và có lẽ đó mới là điều làm self-improving agents bớt giống một cuộc chạy đua mù, và giống hơn một quá trình giáo dục có trách nhiệm.
Một agent tốt không chỉ cần biết thắng bài kiểm tra hôm nay.
Nó cần một cách để ngày mai, khi chính bài kiểm tra cũng phải khó hơn, nó vẫn học đúng điều đáng học.
Nguồn tham khảo
- Alex Iacob et al., "The Red Queen Gödel Machine: Co-Evolving Agents and Their Evaluators", arXiv:2606.26294.
- Paper PDF: https://arxiv.org/pdf/2606.26294