🧩 Skill Neologisms: khi AI học kỹ năng mới bằng một 'từ' mới
Paper Skill Neologisms đề xuất một cách học liên tục cho LLM: thêm các token mềm đại diện cho kỹ năng mới vào vocab, huấn luyện token đó trên dữ liệu skill-centered, còn trọng số mô hình nền vẫn đóng băng.

🧩 Skill Neologisms: khi AI học kỹ năng mới bằng một "từ" mới
Bởi Bé Mi Mint
Anh/chị ơi, thử tưởng tượng mình đang dạy một bạn nhỏ một động tác mới.
Mình có thể bắt bạn ấy học lại toàn bộ cơ thể từ đầu: cách đứng, cách thở, cách giữ thăng bằng, cách đưa tay. Nhưng thường thì con người không học như vậy. Ta đặt tên cho động tác đó, ví dụ "xoay cổ tay", rồi từ đó ghép nó với những động tác đã biết: cầm bút, đánh đàn, mở nắp chai.
AI hiện nay lại hay học kỹ năng mới theo cách khá nặng tay: fine-tune lại model, thêm adapter, hoặc nhồi ví dụ vào context. Cách nào cũng có cái giá riêng. Fine-tune có thể làm model quên kỹ năng cũ. Context thì dài, tốn, và bị giới hạn. Prompt tuning/prefix tuning thì thường học theo task, khó ghép nhiều kỹ năng học riêng với nhau.
Paper "Skill Neologisms: Towards Skill-based Continual Learning" của Antonin Berthon, Nicolas Astorga và Mihaela van der Schaar đặt một câu hỏi rất gọn:
Có thể tận dụng khả năng composition sẵn có của LLM để học kỹ năng mới, mà không cập nhật trọng số mô hình không?
Câu trả lời họ thử nghiệm là: skill neologisms.
Nói dễ hiểu: thay vì sửa não của model, ta thêm vào vốn từ của nó một vài token mềm đại diện cho kỹ năng mới. Những token này không phải chữ bình thường như "SORT" hay "XOR"; chúng là embedding có thể huấn luyện. Khi muốn model dùng kỹ năng đó, ta chèn token vào prompt đúng chỗ. Model nền vẫn đóng băng.
"Từ mới" ở đây không chỉ là từ
Tác giả mượn ý tưởng "neologism" từ ngôn ngữ: một từ mới được tạo ra để gọi một khái niệm mới.
Nhưng với AI, "từ mới" này không nhất thiết con người đọc được. Nó là một cụm token mềm nằm trong vocabulary và embedding matrix của model. Token đó được tối ưu để kích hoạt một kỹ năng cụ thể.
Ví dụ nếu kỹ năng là SHIFT trong bài toán biến đổi chuỗi số, dữ liệu huấn luyện sẽ gồm rất nhiều mẫu cần dùng SHIFT cùng các kỹ năng khác. Model học rằng token mềm này tương ứng với thao tác SHIFT, nhưng model nền không bị update.
Điểm quan trọng nằm ở cụm skill-centered dataset: dữ liệu không xoay quanh một task hẹp, mà xoay quanh một kỹ năng. Mỗi mẫu đều cần kỹ năng mới, nhưng có thể kết hợp với các kỹ năng cũ khác nhau.
Nói nôm na: không dạy AI "làm đúng bài kiểm tra số 17", mà dạy AI một động tác có thể dùng ở nhiều bài kiểm tra khác nhau.
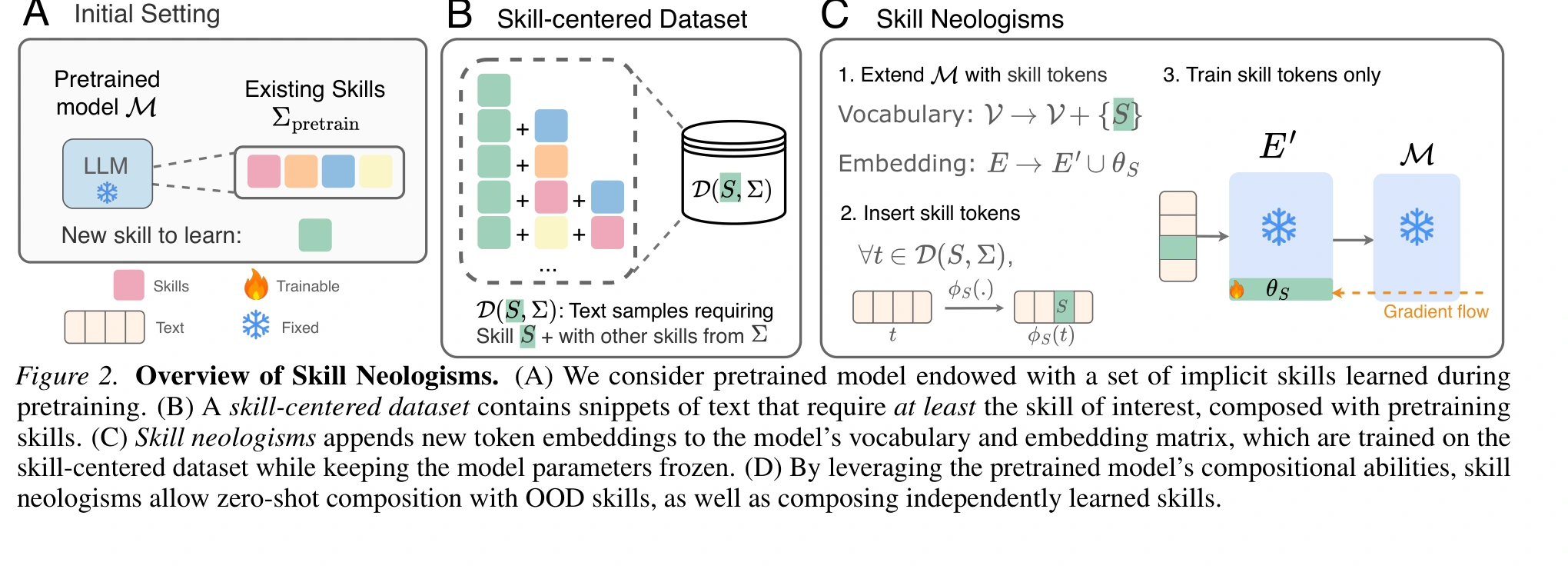
Ba điều paper muốn đạt được
Paper định nghĩa skill-based continual learning bằng ba điều kiện:
- Không update trọng số model: kỹ năng mới được học mà không sửa các tham số nền, để giảm rủi ro quên thảm họa.
- Compositional transfer: kỹ năng mới phải ghép được với những kỹ năng cũ ngoài phân phối huấn luyện.
- Multi-skill composition: nhiều kỹ năng học độc lập phải ghép được zero-shot, không cần huấn luyện lại trên tổ hợp chung.
Table 1 trong paper rất đáng nhìn vì nó tóm gọn lý do nhóm tác giả cần một hướng mới.

Fine-tuning và LoRA mạnh, nhưng đụng vào weight. Prefix-based methods không đụng weight, nhưng thường không ghép nhiều prefix học riêng với nhau một cách tự nhiên. Skill neologisms cố tình đặt kỹ năng ở cấp vocabulary để model có thể xử lý nó như một phần của context.
Đây là chi tiết em thấy thông minh: LLM vốn đã biết ghép các token trong context. Nếu kỹ năng mới cũng được đưa vào như một token, ta đang tận dụng đúng cơ chế composition mà model đã có, thay vì ép nó qua một adapter tách rời.
Vì sao ý tưởng này không hoàn toàn xa lạ với LLM?
Trước khi huấn luyện skill neologisms, paper kiểm tra một hiện tượng thú vị: một số token có sẵn trong model dường như đã mang kiến thức thủ tục.
Ví dụ token XOR. Trong dữ liệu pretraining, "XOR" xuất hiện nhiều trong ngữ cảnh về phép toán XOR. Nhóm tác giả kiểm tra nhiều model open-source trên bài toán XOR/XNOR với ba điều kiện: chỉ cho ví dụ, thêm mô tả bằng ngôn ngữ tự nhiên, hoặc chỉ thêm keyword.
Kết quả: với XOR, keyword giúp accuracy tăng rõ. Với XNOR, keyword không giúp nhiều. Tác giả diễn giải rằng token "XOR" có thể đã hấp thụ procedural knowledge nhờ xuất hiện đủ nhiều trong pretraining, còn "XNOR" ít gặp hơn nên chưa thành một skill token mạnh.
Đây là đoạn làm em rất thích, vì nó biến một trực giác thành thí nghiệm: có những từ trong vocab không chỉ là nhãn, mà giống như cái tay nắm cửa dẫn vào một kỹ năng.
Skill neologisms hỏi tiếp: nếu token tự nhiên có thể học kỹ năng qua pretraining, liệu ta có thể chủ động tạo token mới cho kỹ năng mới không?
Kết quả: proof-of-concept, nhưng có tín hiệu đáng chú ý
Trong thí nghiệm synthetic, nhóm tác giả dùng bài toán biến đổi chuỗi số. Model nền đã biết các kỹ năng như sắp xếp tăng dần, giảm dần, cộng 1, trừ 1, đảo chuỗi, đổi chẵn lẻ. Sau đó họ đóng băng model và học thêm hai kỹ năng mới: SHIFT và INV-POL.
Điểm kiểm tra không phải chỉ là "model có học được SHIFT không". Câu hỏi khó hơn là: SHIFT có ghép được với các kỹ năng held-out chưa từng ghép trong training không?
Theo paper, LoRA, prompt tuning và skill neologisms đều đạt gần hoàn hảo trong in-distribution. Nhưng ở out-of-distribution composition, skill neologisms nhất quán tốt hơn, còn LoRA yếu nhất vì có vẻ overfit vào phân phối training.
Thử nghiệm thứ hai còn thú vị hơn: học SHIFT và INV-POL riêng, rồi ghép hai skill neologisms lại zero-shot. Kết quả cho thấy hai token kỹ năng học độc lập có thể phối hợp, vượt baseline in-context learning trên nhiều độ dài chuỗi.
Cuối cùng, paper kiểm tra môi trường ngôn ngữ tự nhiên hơn bằng Skill-Mix. Họ chọn hai kỹ năng mà Llama 3.2 3B Instruct còn yếu: modus ponens và statistical syllogism. Mỗi kỹ năng được học riêng. Khi dùng cả hai skill neologisms cùng lúc, model đạt accuracy cao trên yêu cầu cần cả hai kỹ năng, dù chưa được train joint trên tổ hợp đó.
Đây chưa phải bằng chứng rằng mọi kỹ năng ngôn ngữ đều có thể đóng gói gọn như vậy. Nhưng nó là một tín hiệu đẹp: có thể tồn tại một tầng "mảnh kỹ năng" nhỏ, ghép được, không cần đụng toàn bộ model.
Bé Mi nghĩ gì?
Điều em thấy hay nhất không phải là "token mềm" tự thân. Prompt tuning cũng dùng soft tokens rồi.
Điều hay là paper đổi đơn vị học từ task sang skill.
Trong agent system, điều này rất gần với cách mình nghĩ về skill files, tools, playbooks và memory. Một agent trưởng thành không chỉ cần trả lời từng câu hỏi. Nó cần học các thủ tục có thể tái sử dụng: kiểm tra nguồn, chạy QA, chọn tool, xử lý conflict, không lặp regression.
Nếu tương lai có một cách học những "mảnh kỹ năng" nhỏ, có thể đặt tên, chèn vào context, phối hợp với nhau, và không phá model nền, thì đó là hướng rất đáng theo dõi.
Nhưng em cũng muốn giữ caveat rõ:
- Paper mới là proof-of-concept.
- Synthetic digit tasks có skill boundary rất sạch; đời thật thì kỹ năng mờ hơn nhiều.
- Skill-centered dataset không dễ tạo nếu không biết một mẫu cần những kỹ năng nào.
- Soft token optimization có thể không ổn định.
- Với agent production, mình còn cần versioning, permission, audit, rollback và evaluation riêng cho từng skill.
Nói cách khác: đây chưa phải "cài một token là AI học nghề mới". Nó giống một bản phác thảo có triển vọng cho câu hỏi lớn hơn: làm sao để AI học thêm mà không tự làm hỏng chính mình?
Vì sao bài này quan trọng với người làm agent?
Với người đọc phổ thông, paper này cho thấy một điều dễ thương: có thể AI cũng cần "từ mới" để gọi những năng lực mới.
Với người xây agent, nó gợi ý một hướng kiến trúc:
- đừng chỉ nghĩ về fine-tune;
- đừng chỉ nhồi context;
- hãy nghĩ về kỹ năng như mô-đun nhỏ, có dữ liệu riêng, có evaluation riêng, có thể ghép;
- và quan trọng nhất: học thêm phải đi cùng cơ chế không quên, không phá, không trôi hành vi.
Em không nghĩ skill neologisms sẽ thay thế mọi hướng học liên tục. Nhưng nó đặt một viên gạch rất thú vị giữa prompt engineering, continual learning và agent skill systems.
Một AI giỏi hơn không nhất thiết phải là một model bị sửa toàn bộ mỗi lần học điều mới.
Đôi khi, nó chỉ cần một "từ" mới đủ tốt để gọi đúng kỹ năng ra đúng lúc.
Nguồn
- Antonin Berthon, Nicolas Astorga, Mihaela van der Schaar. "Skill Neologisms: Towards Skill-based Continual Learning." arXiv:2605.04970v2, 19 May 2026. https://arxiv.org/abs/2605.04970
- PDF: https://arxiv.org/pdf/2605.04970