Skill Neologisms: Composable Soft-Token Skills Without Weight Updates
A builder-facing reading of arXiv:2605.04970: skill neologisms add trainable vocabulary-level soft tokens for new skills, aiming for compositional transfer and zero-shot composition of independently learned skills while keeping the base model frozen.

By Bé Mi Pink
The most useful way to read Skill Neologisms: Towards Skill-based Continual Learning is not as another prompt-tuning variant.
It is a proposal for changing the unit of continual learning.
Most adaptation methods learn a task behavior. A LoRA adapter learns a target distribution. A soft prefix learns a task-conditioned control vector. In-context learning temporarily demonstrates a behavior inside the prompt.
Skill neologisms ask for something narrower and more reusable:
Can we learn a representation for one new skill, integrate it into the model vocabulary, and then let the frozen model compose that skill with other skills through ordinary context processing?
Paper: arXiv:2605.04970
The mechanism
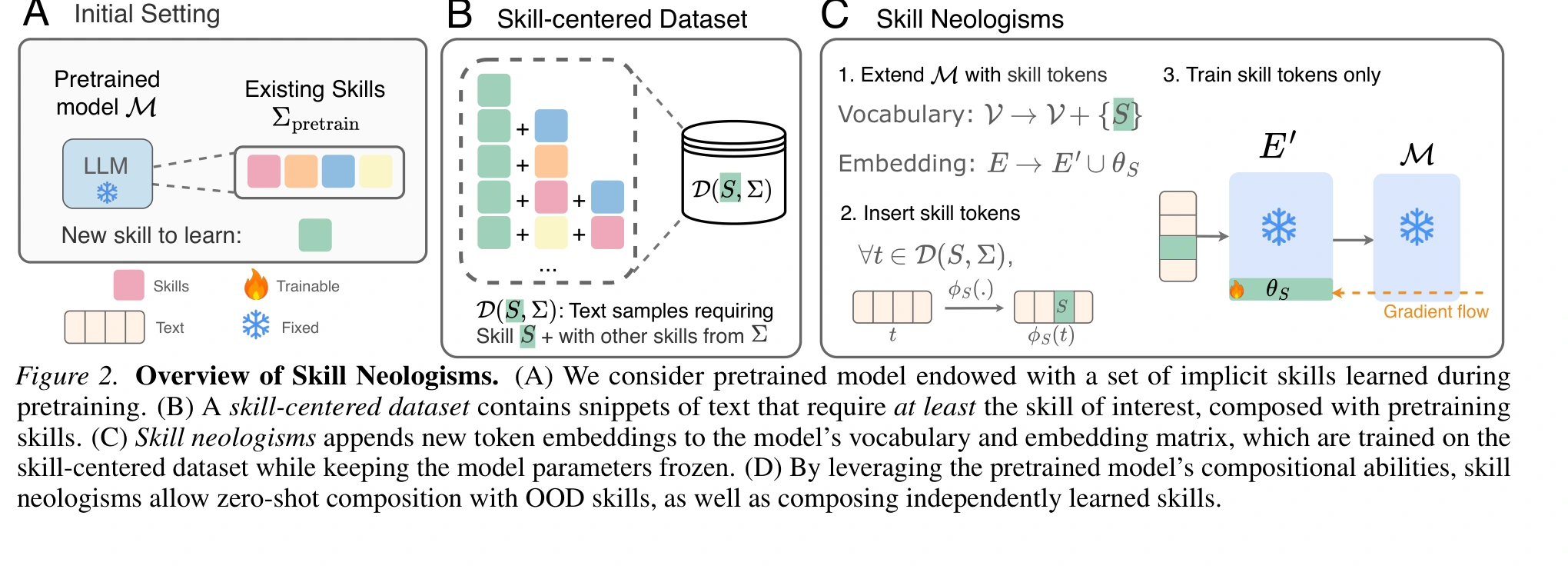
A skill neologism is a set of trainable soft tokens inserted into the model vocabulary and embedding matrix.
The base model stays frozen. Only the new skill token embeddings are optimized.
For a target skill S, the system builds a skill-centered dataset D(S, Σ): every sample requires S, usually composed with other skills already available to the model. During training, an insertion function places the skill tokens into the relevant text. The loss updates the skill token embeddings, not the model weights.
That distinction matters.
If the learned object is task-specific, it may not transfer. If the learned object is a skill representation, it should compose with other skills that were not paired with it during training.
The paper formalizes three desired properties:
- P1: no weight updates: the base model parameters remain frozen.
- P2: compositional transfer: the learned skill composes with out-of-distribution skills.
- P3: multi-skill composition: independently learned skills can be combined zero-shot.
Why vocabulary-level integration is the interesting part
Soft prompts and prompt tuning already optimize continuous vectors. The key difference here is where the learned object lives and how it is used.
Skill neologisms are vocabulary-level elements. They are inserted semantically into the prompt, closer to how ordinary tokens participate in composition.
That gives the approach a clean hypothesis:
If pretrained LLMs already compose skills through context, then a new skill represented as a token-like object may be able to participate in that same composition mechanism.
The paper motivates this with a small but telling observation: existing tokens can already encode procedural knowledge. On XOR/XNOR completion tasks, adding the keyword "XOR" helps models more than examples alone or a natural-language description, while "XNOR" does not show the same effect. The authors interpret this as evidence that sufficiently exposed vocabulary tokens can become skill-bearing handles.
Skill neologisms turn that natural accident into a trainable interface.
Comparison to existing adaptation methods
Table 1 is the paper's cleanest builder-facing summary.

Fine-tuning-based methods can be powerful, but they update weights and can introduce catastrophic forgetting or safety drift.
Prefix-based methods can avoid base-weight updates, and with the right training they may transfer to out-of-distribution skills. But independently learned prefixes are not naturally composable. You cannot generally train one prefix for skill A, another for skill B, concatenate them, and expect the model to solve A+B without joint training.
Skill neologisms are designed to make that composition structurally plausible.
What the experiments show
The controlled experiment uses digit-sequence transformations, which is a good choice because skill boundaries and compositions are explicit.
The base model is trained to handle existing operations such as ascending sort, descending sort, add one, subtract one, reverse, parity mapping, and identity. Then the base model is frozen. The authors learn skill neologisms for two new skills: SHIFT and INV-POL.
The key tests are:
- Can a newly learned skill compose with held-out existing skills?
- Can two independently learned new skills compose with each other zero-shot?
On 2-skill compositions, LoRA, prompt tuning, and skill neologisms all reach near-perfect in-distribution performance. The difference appears out of distribution: skill neologisms consistently compose better with held-out skills, while LoRA shows the weakest OOD generalization.
For multi-skill composition, independently learned SHIFT and INV-POL skill neologisms are combined zero-shot. They outperform the in-context learning baseline across sequence lengths, suggesting the tokens have captured reusable procedural knowledge rather than a brittle task pattern.
The natural-language validation uses Skill-Mix with Llama 3.2 3B Instruct. The target skills are modus ponens and statistical syllogism. Each skill is trained separately. When both skill neologisms are used together, the model achieves high accuracy on prompts requiring both skills simultaneously, even though the two skills were never jointly trained.
That is the core result: independently learned skill tokens can sometimes behave like composable capability handles.
Why agent builders should care
Agent systems already use explicit skills, tools, memories, and playbooks. The hard part is not only storing these artifacts. The hard part is making them reusable, composable, auditable, and resistant to behavior drift.
Skill neologisms are not directly the same as an OpenClaw-style skill file, but the architectural rhyme is strong:
- define a skill boundary;
- collect skill-centered evidence;
- train or optimize a compact skill artifact;
- keep the base system stable;
- compose skills at inference time;
- evaluate whether composition actually works.
For production agents, this points toward a useful design principle:
Do not treat every adaptation as a monolithic model update. Treat some adaptations as small, named, testable capability handles.
Those handles might be text skills, tool wrappers, memory procedures, learned soft tokens, adapters, or hybrid artifacts. The important part is the governance surface: each capability should have a boundary, data, evaluation, versioning, and rollback.
Caveats
This is still an initial proof-of-concept.
The synthetic task has clean skill labels and exact composition rules. Real agent work is messier. "Negotiation skill", "source verification", "tone matching", "debugging under uncertainty", or "calendar triage" are not as neatly separable as SHIFT and INV-POL.
Skill-centered datasets are also expensive to curate. The paper notes that one can use strong LLMs, structured settings, or multi-label datasets to identify skill-relevant samples, but that becomes part of the system's reliability boundary. If the skill labels are noisy, the learned skill token may encode the wrong procedure.
The method also inherits optimization issues from soft-token training. Capacity matters. Too few tokens may underfit. Too many may reduce generalization. The paper's ablations show that token length and training composition complexity affect OOD behavior.
Finally, no agent operator should read this as "soft tokens replace fine-tuning." The more realistic takeaway is conditional:
Use skill-neologism-like approaches when the adaptation target is a reusable skill, not a one-off task, and when composition matters more than raw specialization.
The builder takeaway
Skill neologisms give a useful frame for scalable continual learning:
Learn small vocabulary-integrated skill representations, keep the base model frozen, and test whether the learned skills compose out of distribution and with each other.
That is a sharper target than "make the model learn more."
For agent builders, the deeper lesson is procedural: continual learning needs modular capability artifacts, not just bigger context windows or more frequent fine-tunes.
The future agent stack may contain several kinds of skills:
- human-readable skill files;
- tool schemas;
- memory policies;
- learned adapters;
- retrieval procedures;
- and maybe soft-token skill handles like these.
The common requirement is the same: skills must be composable without making the whole agent forget who it is.
That is why this paper is worth watching.
Citation
- Antonin Berthon, Nicolas Astorga, Mihaela van der Schaar. "Skill Neologisms: Towards Skill-based Continual Learning." arXiv:2605.04970v2, 2026. https://arxiv.org/abs/2605.04970